Massachusetts Institute of Technology
Department of Electrical Engineering and Computer
Science
6.863J/9.611J Natural Language Processing, Spring,
2004
Laboratory 3, Component III:
Context-free parsing, Writing Grammar Rules
Handed Out: March 17 Due: April 12
1. Introduction: Goals of the Laboratory & Background Reading
The main aim of this
laboratory is to give you a brief exposure to building “real” grammars, along
with an understanding of how syntactic phenomena interact with context-free
parsing algorithms., along with an “initiation'' into the particular way of
handling the syntactic phenomena we describe.
In addition, you will learn how to use features to simplify
grammar construction. For all of this, you will use the python Earley parser as
described in Laboratory 3a. Finally, we
will want you to understand the trade-off between the simplicity of the grammar
and its precision in terms of covering more and more detailed grammatical
phenomena:
·
Given a simple
context-free ``starter'' grammar that we provide, you will extend this grammar
to handle a slightly wider variety of syntactic phenomena with different kinds
o of verb arguments and embedded sentences.
·
You'll then add
rules to handle a very small number of subject-verb agreement examples.
·
In the third
part, you will add rules to handle questions such as “Which detectives solved
the case?”
·
Then, using features,
you'll write an augmented context-free grammar to cover the same examples
as in parts 2 and 3, and compare its size to your grammar that does not use
features.
·
Finally, we shall
see how to interface the parser to Kimmo. [deferred in this lab!]
Similar to previous
labs, your completed laboratory report should be written as a web page, sent to
havasi@mit.edu, and contain
these items for each of the four parts above:
A description of how your system
operates. How does your system handle
each of the syntactic phenomena described below? Include a description of the rules that were used to encode the
relevant changes to the grammars and how these were implemented (e.g. “I added
the rule VP®,”... “In order to
implement this rule, we had to …”). If appropriate,
mention any problems that arose in the design of your grammar.
·
Your
modifications to any initial grammar rule files that we supply to you.
·
A record of a parser run on supplied the test
sentences – you can use the command
line options of the Earley parser in
terminal mode to record runs to an output file, and print both postscript and
latex formatted trees – use the command earley –h to get a list, e.g.:
options:
-h, --help show this help message and exit
-t, --text run in text mode (faster)
-bFILE, --batch=FILE Batch test: parse all the lines in a file
Text/batch mode options:
-v, --verbose output all edges that are generated
[default]
-q, --quiet output only the generated parses
[default in batch mode]
-l, --latex output parses as LaTeX trees (using
qtree.sty)
-d, --drawtrees show parse trees in a GUI window
(NONBATCH only)
-oFILE, --output=FILE
send output to a file
·
Your
feature-based context-free grammar for the same sentences, as well as a size
comparison to your feature-free context-free grammar for these sentences. We shall also ask you to generalize your
result, if possible (see below).
General Background reading for this Laboratory
Running the Earley
parser
(The
following paragraph is review from the previous laboratory.) You invoke the
Earley parser this way:
athena% cd /mit/6.863/python-earley
athena%
earley
This
will pull up the following window, in which you can load your own or a demo grammar
and lexicon, or just type one in.
Grammar files have the extension .grm. (These files are otherwise
just plain text files, so you can edit them any way you want – the Earley
window has a fairly complete editor so you can find/search & replace; and
so forth to edit a grammar file right there – but you should save the result in
your own dir.)
For
this laboratory, we want you to load a very simple ‘starter’ grammar in the python-earley
directory. The file is lab3b.grm. (Do not load the
grammar for lab 3a!) To load grammar 3b, simply go to the “File” menu, click “Open”, which
will pull up the list of .grm files in the directory, and select lab3b.grm. Please
do that now. Your window should now
look like the one below – if it doesn’t, something is awry and you should ask
us! The grammar file format shown below is what you should follow for this Lab:
separate lines for each rule; a separator between rules and lexicon. Note that
a word can have more than one part of speech.
Also note that the way we write the lexicon is a bit different from the
chart parser – just the word followed by one or more part of speech categories.
Important: Your
grammar file should always include at least one rule that
is in the following form: Start ® … ;
for instance, Start ®
S. The order of rules in the Rules
section does not matter. The order of
lexical items in the Lexicon section does not matter. Once you have loaded a
rule file, you can parse a sentence by typing in the sentence in the panel
below the grammar, and then pressing “Parse”. This will pull up a window
similar to the chart windows for the previous examples, but again different in
a few details. You can proceed to parse
a sentence by hitting the “Run parser” button on this new window. Again as before, this will trace out the
creation of each edge as it is placed into the chart. The “Step” checkbox works
as before – you can trace through parse execution, edge by edge. There are no strategy control buttons,
because the whole point of the Earley algorithm is to fix a particular strategy
for edge construction.
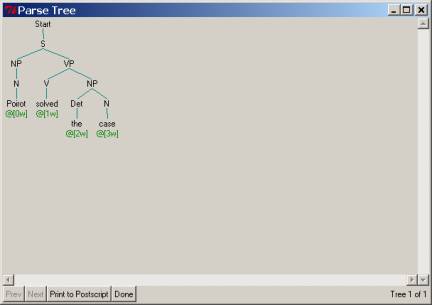
If the
parse is successful, a window will pop up with a tree display for the parse. You can print this to postscript. If there
is more than one parse, you can scroll through them using the “Next” and “Prev”
buttons on the window, inspecting or printing each one as you want. The parse
tree output for the sentence “Poirot solved the case” should look like the
following:
Pressing
the “Show Log” button will display the actual edges as they are created, their
label, and their extent, as discussed in section 2.3. This is most helpful in
diagnosing exactly where a parse goes awry.
2.1 Grammar 1: Rules for declarative sentences
The grammar that you already have can parse these sentences (and a bit more),
which we call “simple declarative sentences” (note that you do not have
to provide an end of sentence marker like a period):
1.
Poirot solved the case
2.
The detectives lost the guns
3.
Poirot thought
4.
Poirot sent the police
5.
Poirot sent the solutions to the police
You've already seen the structure the parser produces for the
first sentence in the list above. For
the second, third, and fourth sentences below are corresponding pictures of the
resulting parse trees.
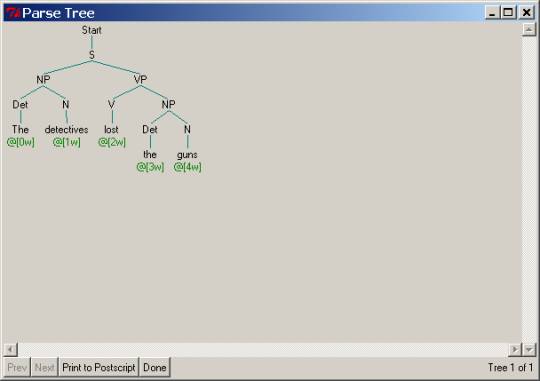
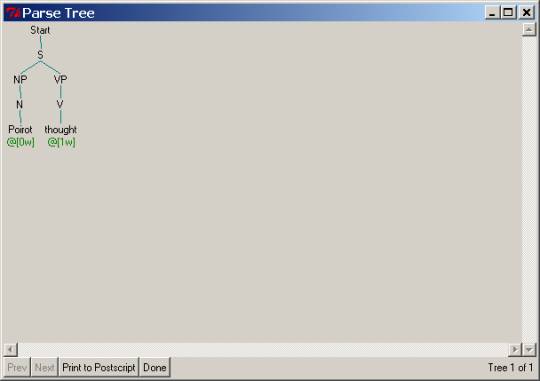
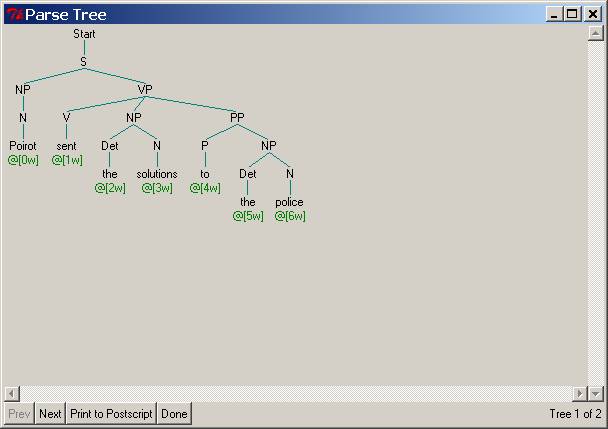
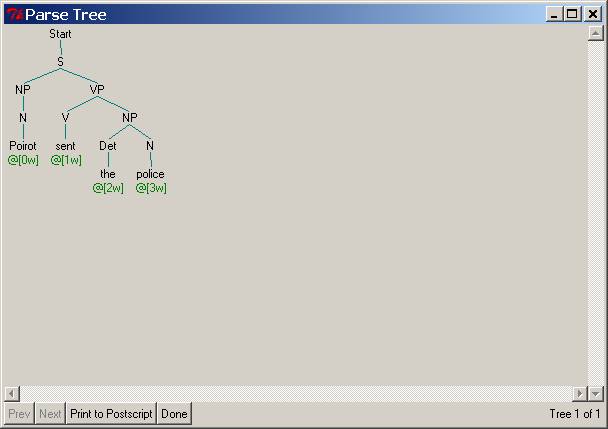
When we ask you below to “extend the parser to produce correct
parses,” we mean that your revised grammars should produce parse trees exactly
like these and no others. Your revised grammar should not produce
‘extraneous’ parses. This is important
– your grammar should not ‘overgenerate’ in the sense of being able to parse
“ungrammatical” sentences o assign parses (structures) that are incorrect to
otherwise correct sentences. After all, if overgeneration were allowed, then
one could simply write very, very general rules like S® w*, that is, a sentence is any string of words
at all. This grammar could indeed “parse” any string of words, but the results
would not be very informative. (On the other hand, you might rightly question
whether our grammar should or should not be able to parse ‘ill-formed’
sentences – one thought is that it should try to get through as much as it can,
to understand such a sentence. That’s a
legitimate point – we return to it in later lectures. But for now, take the structures we give as a ‘gold standard.’)
For this
reason, your grammar should not allow examples such as the following,
where we have (artificially) marked the ill-formed examples your grammar should
not be able to parse with an asterisk in front. Just as in the Kimmo lab, the asterisk is not
part of the input! It simply indicates that the sentence is to be rejected as
yielding no parses with respect to your grammar, or as in case number 4 below,
it should block a particular parse structure.
These are all violations of the subcategorization (argument
requirements) for their respective verbs.
1.
* Poirot solved (invalid because solve requires an object
as an argument)
2.
* Poirot thought the gun
(invalid because think requires either no argument or else an
argument that is a certain kind of object, namely, a full proposition or
sentence)
3.
* Poirot sent to the police
(invalid because send requires two objects)
4.
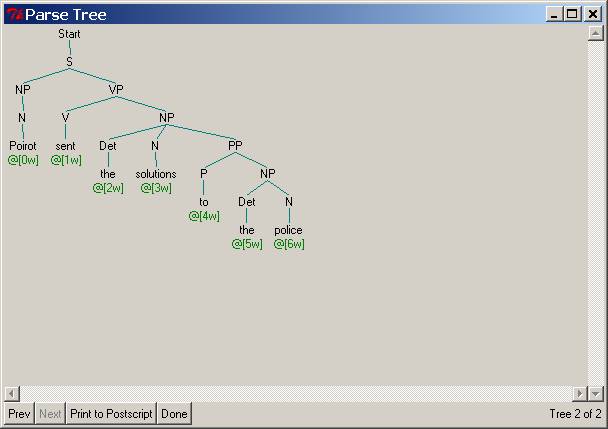
*Poirot sent [the solutions to the police] (invalid because we do
not want to get the parse where ‘to the police’ modifies ‘the solutions’) –
that is, we want to block the parse as shown below:
Your assignment in this
section. More
generally, at it stands the lab3b grammar for the parser does not correctly
distinguish between verbs that take zero, one, or two arguments (with some
arguments perhaps optional). It also does not block the improper attachment
of “to the police” to “the solutions”
in the fourth case above. Please augment
the lab3b grammar by adding new verb subcategories so that sentences 1-4
immediately above, such as Poirot solved, will be rejected by the parser
(no output), while Poirot thought will still be OK. We want the new grammar to be able to parse
all the sentences it could before, of course. You will also have to add/modify
the dictionary entries. You can edit
your grammar file in the editing input window to do this, but be sure to save
it somewhere later!
Note: A list of all the example sentences you will have to handle
in lab3b, listed section by section, along with the starred (ill-formed)
sentences your parser must reject, is given in the file lab3b-sentences.txt in
the python-earley directory.
Important
note: Probably the
most common error is to forget to include a word with its part of speech, or to
mistype a word. If this is so, the
parser will never construct a 1-token edge for that word – you should see that
right away when you try to parse the sentence.
Hand in
for your lab report: Your modified grammar rules and dictionary, and output from the
parser illustrating that it has parsed these new sentences correctly, while
rejecting the first three starred sentences above. In the fourth case, please show via the output panel that the
single, correct parse is produced for “Poirot sent the solutions to the
police”.
In this section, as in all the remaining sections below, when we say to illustrate that your grammar
works as advertised you should include snapshots of the final chart matrix
and/or edges, which will show either the correct derivation or how the parse
was blocked in the case of ‘starred’ sentences.
2.2 Grammar 2: Verbs that take full sentences as arguments
Still other verbs demand full propositions – sentences – as arguments:
1.
Poirot believed the detectives were incompetent
2.
Poirot believed that the detectives were incompetent
Here, the verb believe takes as an argument a full Sentence or Proposition:
the detectives were incompetent.
As the second example immediately above shows, that may or may
not be present before such ‘embedded sentences’ in English (though not, for
instance, in Spanish). This will
require further elaboration of the subcategories of verbs, as you may
appreciate.
We shall require a special structure for such sentences, as described below and
as shown in the figure that comes next.
In order to accommodate the possibility of that, and for other
linguistic reasons, the Sentence phrase itself is written so that the actual
combination of that-S forms a
phrase called S-bar. The item before
the S is called its complementizer, abbreviated
COMP, and is filled by words such as that, who, which,
etc. in English. You may think of this Comp position as the place filled by a
kind of semantic ‘operator’, sometimes phonologically empty (as in a main
sentence, like #1 above). The idea here
is to make full sentences fit into the uniform framework of Verb Phrases,
Prepositional Phrases, Adjective Phrases, and Noun Phrases – the first item in
English phrases is a ‘functor’ like a Verb, Preposition, Adjective or a
Determiner, and what follows is the ‘argument’ to the functor. So, for a sentence, the Comp position holds
the functor, and the Sentence is the argument. You don’t have to worry about the semantics of this now – but
simply adopt this form for the parses here.
Here are the parse structures corresponding to the two believe sentences. We would like you to modify your grammar to
produce these parse trees as output. As you can appreciate, one could
immediately see what the corresponding context-free rules ought to be, just by
looking at these tree structures. So,
in the figure below we have given almost the correct parse trees – we
have deliberately wiped out some information about the verb subcategories. It will be your job to figure out the
correct verb subcategories and to write the grammars to produce the parse trees
as shown (adding the detail needed for the verbs).
Poirot believed that the detectives were incompetent
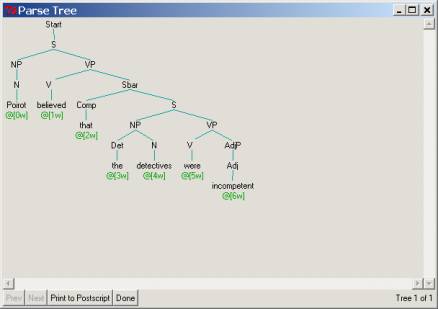
Poirot believed the detectives were incompetent
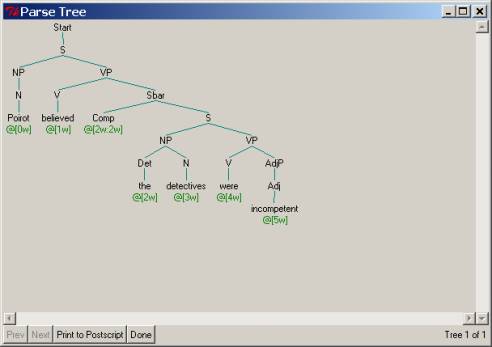
Hand in for your lab report: Your modified grammar rules and dictionary, and output from the parser
illustrating that it has parsed these two new sentences correctly, while still
working properly on the sentences from section 2.1.
2.3 Grammar 3: Unbounded Dependencies and Questions
As our next example of grammar
augmentation, you will now try to add rules to handle certain kinds of English
questions. This will involve implementing the augmented nonterminal (“slashed
category”) notation discussed in class –the augmentation of a context-free
grammar with new `` nonterminals and rule expansions.
Listed below are examples from each of the construction types your new grammar
should handle, as well as examples that it should reject. The sentences that
should be rejected parses are marked with asterisks in front. Of course, as usual these asterisks are not
part of the actual input sentence! For these sentences your parser should
return no parses. Note also that
there are no question marks at the end of these sentences – this isn’t
needed! Such sentences are called ‘wh
question’ sentences, because there’s a wh-phrase like ‘which…’ or ‘what…’
at the beginning of the sentence.
2.3.1
Question Formation
1.
Which case
did Poirot solve
2.
Who solved
the case
3.
Which
solution did Poirot send to the police
4.
Which
detectives solved the case
5.
Which
solution did Poirot believe that the detectives sent to the police
6.
*Which
solution did Poirot send the gun to the police
7.
*Who solved
In these examples, we will again explain the structures we want you to output
with your parser. This will assist you
in adding context-free grammar rules to be able to parse them. Your job will be
to write those rules.
2.3.2 Step
1.
You should
first note that your new grammar will have to handle verbs like solved, send,
as well as verb sequences that include that peculiar English verb do, as
in ‘did solve’, ‘did send’, and ‘did believe’. To do this, you should first add ordinary
(non-augmented) nonterminal rules to parse the corresponding examples without ‘which
case’, etc:
1.
Poirot did
solve the case
2.
Poirot did
send the solution to the police
3.
Poirot did
believe that the detectives sent the solution to the police
What is the
structure you should adopt to accommodate did? Note that do
actually has absorbed the ‘tense’ marker that is usually part of the verb: in
the sentence John kissed, ‘kissed’ has a tense marker (i.e., past), but
in John did kiss, it is do that has changed to did, and
the verb following did is always without tense – i.e., solve,
send, believe. How to do this? There are several possibilities, but one
that was adopted by the creators of the ‘augmented context-free grammar’
approach was simply to include a new phrase called “DOP” (for a “do phrase)
that is part of an auxiliary verb form:
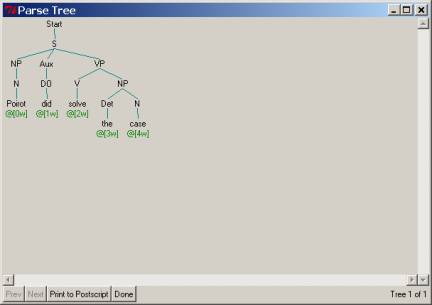
2.3.3 Step
2.
Now you have
to expand your grammar to handle the ‘inverted’ form seen in questions, where
the auxiliary verb is switched with the subject noun phrase:
1.
Poirot did
solve the case ® Did Poirot solve the case
2.
Poirot did
send the solutions ® Did Poirot send the solutions
3.
Poirot did
believe ® Did Poirot believe
The following parse tree suggests the rules that you will have to
add to capture these possibilities.
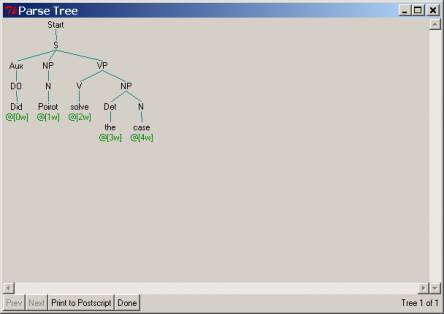
2.3.4 Step 3.
You will next note that the wh-phrases such as which case,
which solutions, and which detectives themselves are Noun Phrases
(NPs), but of a special sort: the determiner that is at the front of the noun
is a wh-word such as which, what, etc. – and it is these sorts of NPs
that are displaced. So, you would have to write new NP rules that form what are
called ‘wh’ NPs: let us label these as whNP and provide this
parse tree to suggest the rules needed to describe them. Note that this
sentence does not show the wh-phrase in the correct question positions.
(You might be getting winded at this point – for good reason. Shouldn’t there be some way to do this
automatically?) Such rules would also
have to parse the ‘echo questions’ Did Poirot solve which case? as shown
after this snapshot.
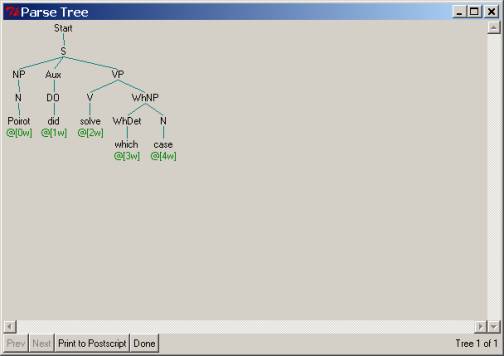
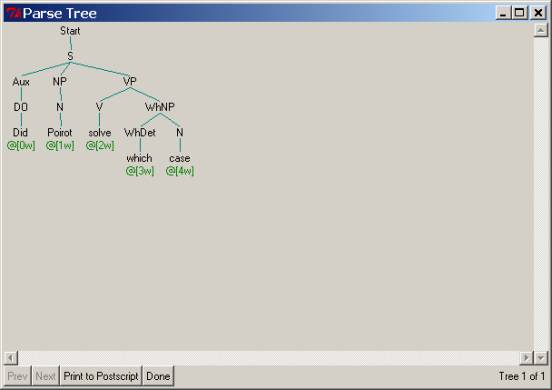
2.3.5 Step 4.
We are finally ready to tackle the wh-question sentences
themselves. In sentences like these, we find the wh-Noun Phrases displaced
from their canonical position of interpretation, usually the object of the main
verb. Instead, we find a ‘gap’ – a
phonetic null – in this position, e.g, after solve below, with the
wh-phrase itself being fronted to the beginning of the sentence:
Which case did
Poirot solve ___
In the literature this is often written by labeling the position
after solve a ‘gap’ (G) and which case a ‘filler’ (the item that
fills the gap), F. This is of course notation that does not ‘show up’ in the
way the sentence looks as input:
Which
case-Filler did Poirot solve Gap
It is more convenient to think of the Filler which case as
being ‘displaced’ or ‘moved’ from its canonical position, the Gap, as we shall see.
We already know that which case
forms a Wh-NP (a Noun phrase with a ‘wh’ property, because of the determiner which). Where should it go in the
output parse tree? We don’t seem to
have a position for it. At this point,
it is useful to recall our form for embedded sentences – we said they were
phrases of type S-bar, made up out of two parts: Comp and S. If we apply that idea uniformly, then we may
imagine that which case was ‘launched’ from its canonical position
after solve, and the position underneath Comp provides
a ‘landing site’ for the phrase, as shown in the final output parse tree
below.
NOTE that this tree
is not its correct, final form because we have left which
case in its ‘starting position’ as well.
So, in the next step we’ll have to get rid of that second which
case – you might think of it being ‘not pronounced’, following some rule of
‘economy of effort’ to ‘not say something you’ve already said’ (obviously not
followed in my case, but there you go).
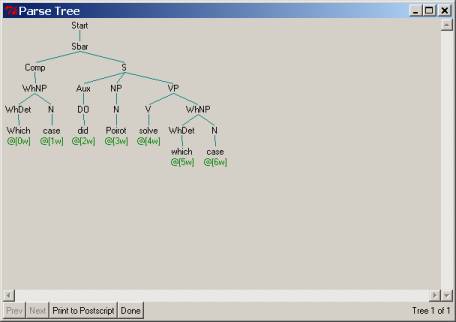
How do we
‘erase’ the second occurrence of which case? We simply must introduce a rule to ‘erase’ whNPs generally, that
is, having nothing at all on the right-hand side of a rule (e.g., WhNP® ). Adding this to our
grammar will give us the following output parse:
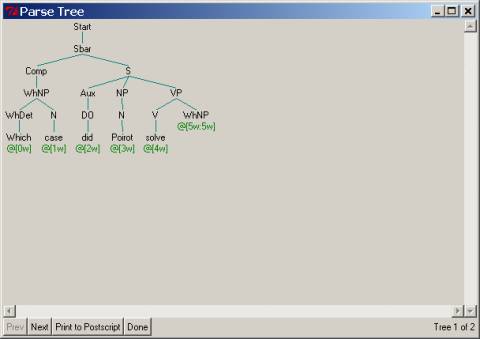
You might be
beginning to wonder what you have to do to build the grammar to handle
questions – haven’t we given you all the rules? No. Somehow we must
output the example above while blocking an example such as which case
did Poirot solve the case, or which case did Poirot solve the police or
Which solution did Poirot send the gun to the police. This is because the ‘argument’ to the
verb solve is the displaced which case, so the position after solve
is already filled and cannot be occupied by another argument such as the
police. Further, we do not want to
allow an empty argument if there is no whNP out front, i.e., we don’t
want the parser to accept Did Poirot solve.
To do this,
you’ll have to add new grammar rules and new nonterminal names to ‘remember’
whether or not a WhNP has been encountered.
This ‘augmented’ context-free grammar approach, known as Generalized
Phrase Structure Grammar, does this by means of special nonterminal names. Alongside rules such as S®NP VP, we add rules such as these:
Start® Comp S-WhNP
Comp® WhNP
S-WhNP ® NP VP-WhNP
VP-WhNP® V WhNP
WhNP®
Note that
here nonterminal names such as S-WhNP are indivisible and atomic – they
are single names, just like ‘VP’. You
should be able to see that their purpose is to allow the generation of an
example such as which case… with a phonetically empty WhNP after the
verb. These rules are not
complete – it is your job to finish them off properly to handle the example
sentences 1-4 at the start of this section.
In addition, you will have to make a design decision about a sentence
such as ‘Who solved the case’. Is the
‘who’ in the position of a subject NP as usual, or is it too ‘displaced’ to the
position in Comp? Note that this is
difficult to tell from the surface since the displacement is invisible
to the eye (or ear). We shall leave the
choice to you, but urge you to attempt a uniform solution first – i.e., one
where the WhNP is displaced to the Comp position. In addition, you should reflect on why this
is a choice at all – why would it be better to adopt one solution rather than
another?
Finally, as
before, you must make sure that your grammar does not overgenerate, and parse,
incorrectly, the sentences:
1.
* Who solved
2.
* Which
solution did Poirot send the gun to the police
3.
* Which solution
did Poirot solve which solution
4.
*Which case
did Poirot believe the police
Hand in for your lab report: Your
modified grammar, along with appropriate parsing documentation (e.g., snapshots
of the chart) and parse tree output demonstrating that your grammar will
produce the correct output parses for sentences 5-9 below, as well as rejecting
the ‘starred’ sentences 1-4 immediately above. (Note that as a side effect
your parser should also be able to parse do-questions such as Did Poirot
solve the case, etc., but you needn’t
document these.)
5.
Which case
did Poirot solve
6.
Who solved
the case
7.
Which
solution did Poirot send to the police
8.
Which
detectives solved the case
9.
Which
solution did Poirot believe that the detectives sent to the police
2.4 Grammar
4: Agreement, features, and grammar size
In English, there is agreement in person, number, and gender between the
subject noun phrase and the verb phrase.
Thus we have:
1.
The solution
solves the case (singular noun and singular verb – an s as the suffix of
solve)
2.
*The
solution solve the case (singular noun, plural verb – no s on the end of
solve)
3.
The solution
that Poirot sent to the police solves the case
English is fairly impoverished with respect to agreement phenomena. As you saw in Laboratory 1b, many other
languages are far richer.
How should
one encode such ‘feature agreement’ into a context-free grammar? We shall try two approaches. In this section, we want you to simply
revise the system you currently have, using just atomic nonterminal
names, so that it will correctly parse the following sentences, while rejecting
as unparseable the starred sentences, as usual:
1.
The solution solves the case
2.
* The
solution solve the case
3.
The
solutions solve the case
4.
* The
solutions solves the case
5.
The
solutions that Poirot sent to the police solve the case
6.
*The
solutions that Poirot sent to the police solves the case
Hand in
for your lab report: (1)
Your
modified, atomic nonterminal grammar rules and dictionary that will correctly
parse all the unstarred sentences, while rejecting the starred sentences, along
with output demonstrating that your new grammar works as advertised.
(2) Grammar
Size. Please calculate the grammar size, |G|, in terms of the total
number of nonterminals in your grammar (that is, the total number of symbols in
your ‘Rules’ section – you don’t have to count the arrow!), and compare its
size to the that of your final grammars from sections 2.2 and 2.3 above –
please tell us what the percentage size
increase is from your version 2.2 and 2.3 grammars to the grammar that
handles agreement in this section. Save your results for the comparison in the
next section.
2.5 Grammar
5: Using features
2.5.1
Features and grammars As
you can see, our grammars keep getting larger and larger. There is something inherently ‘wrong’ with
this approach: the rules for singular and plural subject and verb agreement are
stated separately, when clearly they are the result of a single
‘agreement’ phenomenon. There should be
one rule, but we have written two.
Following the principle of modularity, it would be more accurate and
perspicuous to state the rules that a sentence is a noun phrase followed by a
verb phrase separately from the agreement rules that are superimposed
‘on top of’ this basic one. This also follows the idea of a ‘right’
representation: if we change, say, the fact that there is no agreement, then we
need only negate one statement, and it is impossible to retain agreement
just for ‘singular’ without also retaining agreement for ‘plural’
features. In short, then there would be
one phrase structure rule and one rule for the feature agreement.
Note where
agreement is checked. As suggested
earlier, we want to reduce all syntactic predicates to operate on the basic
‘units’ of representation in syntax – either dominance, or adjacency. In the
case of agreement, we check features based on adjacency. For example, the subject NP is adjacent
to the VP. That must mean that the VP
too has features: these are inherited ‘from below’ by its verb. This makes sense according to our notion
that a VP is merely the ‘scaffolding’ that supports a verb – if a verb is 3rd
person or 1st person (e.g., she solves vs. we solve),
then that property is somehow projected from the verb entry to the VP (we show
below how this is implemented in our Earley parser).
The notion
of agreement is essentially that of compatibility or consistent variable
value assignment – features that the language says should agree must not
conflict. For instance, in other
languages, and residually in English for instance, a determiner and its noun
must agree in number: we have this book (singular) but these books
(plural). If a feature conflicts in its value, the sentence seems odd: this books. Note that this means that
if a feature happens not to be present, then there is no effect since
there is no conflicting feature value to cause trouble: since the does
not retain a number feature, we have either the books or the book. English also has a case feature, a
historical remnant of Latin: we have, I saw her (her is
the object of the verb, or ‘objective’ case); vs. She saw Mary
(she is the subject of the verb, or ‘nominative’ case).
We can
conceptualize all this as follows. A feature
is a [feature-name feature-value] pair.
For example, [Person 1] is a possible feature, denoting first-person. We place feature name and feature value pairs
in square brackets. A feature set
is an (unordered) collection of feature names and feature values, separated by
commas. For example, this feature set
consists of two features, Pers and Plural.
The Pers value is 3 (‘third’ person, as in ‘She solves’ rather than ‘You
solve’); and the Plural value is –, arbitrarily denoting not plural, or
singular:
[Pers
3, Plural -]
Some features may be designated agreement features, and required
to match, more precisely be consistent with other features, as described
below.
For instance, Poirot in Poirot is hungry could be
written as having the feature set [[Pers 3], [Plural -]], since Poirot is not plural and is
third person (as opposed to I, which is ‘first person’.) Similarly, the singular verb sleeps
could be labeled with the features [[Pers 3],
[Plural -]]. Since the features person, number, and
(sometimes) gender appear so frequently together in English, we shall admit the
abbreviation Agr to stand for all three. Thus for Poirot we may attach the feature [Agr
[Pers 3, Plural -]]. In this case, we have a feature name Agr whose value is itself a list,
namely, Pers 3, Plural -]. Feature names are, of course, arbitrary,
but hopefully mnemonic. The feature
values, in contrast, are determined by the way the language works – in English,
an item can be either Plural (marked [Plural +]) or not (marked [Plural -]).
The
following parse tree for Poirot solves the case illustrates how the
Earley parser output will change after we have added feature agreement for NPs
and VPs. Note that the feature values
from the lexicon are ‘percolated up’ to be checked at adjacent nodes in the
tree:
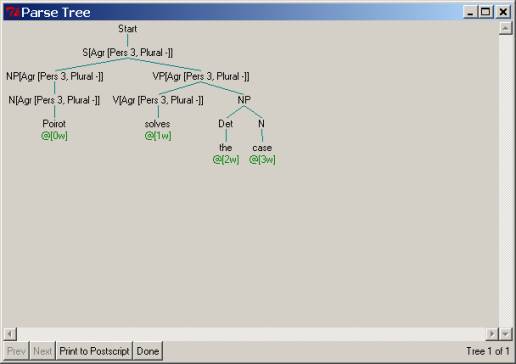
Feature
implementation in the Earley parser
To implement
feature agreement in the Earley parser we add variables and feature
structures to context-free rules and to lexical entries. We
let the grammar writer specify which features on the lefthand side of a rule
must agree with those on the righthand side by using variables, in the following form:
[feature-name
?x]
where the feature-name
is separated by one or
more spaces from a variable specifying a feature value.
(We precede
variables with a question mark – otherwise, the names are arbitrary.)
For example,
to assert that the Plural feature of the subject NP and VP must
agree with the Plural feature on the S(entence) we can write a modified rule this way:
Original rule: S
-> NP VP
New rule: S[Plural ?x] -> NP[Plural ?x]
VP[Plural ?x]
It is the
consistency of variable bindings that is used to check agreement. This is a
simplified (nonrecursive) version of unification that you may have seen
in 6.001 or 6.034. The value for ?x on the right-hand side of the new rule will
be filled in from below for either NP or VP or both in the parse tree (see our
parse tree output example) and bound
to the value + or – (for plural or singular). The binding for ?x must be consistent across the entire rule, so the effect of this
statement is twofold: ensure that the
value for the Plural feature matches in the NP and VP; and coerce a value for
the Plural feature for the S. Ultimately, the feature values will come from
lexical items at the leaves of the tree, either specified in the grammar rule
lexicon or passed through by a morphological analyzer like Kimmo. For example, the Plural
features for the NP
could be passed up from either the Determiner or the Noun. Thus we could provide the following entry
for a Noun such as Poirot. Note that we simply add to the
usual part of speech entry in the parser lexicon. Since feature-value pairs
comprise sets, the order of feature-values within a bracket is immaterial:
Poirot N[plural
-]
Similarly,
for a verb such as solves we could write this in our grammar lexicon:
solves V[plural
-]
We may also
label a finite set of feature values with a separate feature name label, for
abbreviatory purposes, whose value is itself a list of features in square
brackets. For example, the features person, number, and gender can be grouped
as a single ‘agreement’ feature, Agr.
Note, importantly, that as always there must be a space between
the feature name Agr and its list of values (in this case also in square
brackets):
S[Agr ?x] ->
NP[Agr ?x] VP[Agr ?x]
Poirot
N[Agr [pers 1, plural -]]
Solves
V[Agr [pers 1, plural -]]
In this
case, the value of ?x
will become bound to the
value of the Agr feature for Poirot, i.e., [pers 1, plural
-]. Note that this variable
assignment is consistent with the feature value for solves. If the
lexical item were solve then the entry would be, e.g., V[Agr
[pers 1, plural +]] and
this would not match with the value previously assigned to ?x,
namely, – . Thus the consistency check would return
failure, as desired.
Importantly
for our purposes, we do not allow feature structures to be nested beyond
this, nor do we allow nested variables.
For example, the following structure is not admissible:
solves V[[Some-Verb-feature [Agr [pers 1, plural -]]]
A lexical entry
can also specify a feature value that will not be checked for consistency
because the corresponding context-free rules do not mention it. For example, suppose we expanded the verb
entry for solves to include a binary value as to whether the verb is inflected
for tense or not. Thus in Poirot
wants to solve the case ‘solve’ is in its infinitive form; in Poirot
solves the case ‘solves’ is in its ‘finite’ form. We call this feature finite, abbreviated ‘fin’, so we
label solves with the feature value pair [fin +], and (to) solve with the feature
value [fin -]. Now our lexical entry
would look like this:
solves V[fin +, Agr
[pers 3, plural -]]
To check
this feature we must mention it in a context-free rule, using another variable
name for the new feature to distinguish it from the agreement feature, for
instance:
VP[fin ?y, Agr ?x]
-> V[fin ?y, Agr ?x]
Now the
lexical entry for solves can be something like this:
solves V[fin +,
Agr [pers 1, plural -]]
When this
entry is looked up in the course of
Earley parsing, it has the effect of binding ?x to + and ?x to [pers 1, plural -]. Thus, the feature structure now associated
with V would now be:
[fin +, Agr [pers
1, plural -]]
as desired. Since the augmented context-free rule
requires that the variable binding be consistent on both sides of the
derivation arrow, this coerces the VP to have the same feature structure, also
as desired. But if we omitted all
mention the [fin ?y] specification in a rule, only the Agr feature (more precisely, its components)
would be checked and passed up the tree.
Alternatively,
these features could be specified via morphological analysis, using Kimmo. Here we shall assume that features are given
in the context-free grammar dictionary, and follow along with our example.
More
generally, features are written just as they are defined, as (unordered) sets
in the form of feature name and feature value pairs, each pair separated by
commas.
[feature1
value1, feature2 value 2, … , feature n value n]
To repeat: additionally,
a feature name may itself be an abbreviation for a (finite) bundle of features,
e.g., the arbitrary name Agr
can abbreviate the list
for person, number and gender:
[person value,
plural value, gender value]
can be also written as:
[Agr [person
value, plural value, gender value]]
The value of this
abbreviation is that it lets us compactly write rules such as the one for
subject-verb agreement above, without having to always explicitly mention the
three agreement features by name. (Reminder: Note also that while Agr
may be thought of as a
feature name that itself has a set of feature-values as its value, in general
‘nested’ feature-value combinations are not admissible – that is to say,
the value of a feature cannot itself be another feature, recursing arbitrarily.
Feature-value structures can be nested to a depth of exactly 1 - as in the example for Agr
above. An arbitrary depth for feature-value
structures is permitted in some feature agreement computational systems for language
processing, but is arguably not required for natural languages. It also boosts computational complexity, as
we remark briefly below and in lectures to come.)
Note also
that not all features need be checked on each component of the
righthand side of a rule. For example, suppose we had an S expansion rule of
this kind, with an Auxiliary verb (Aux) (e.g., for Poirot will solve the
case):
S -> NP Aux
VP
We could
enforce agreement between the NP and the VP, but not the Auxiliary verb, simply
by writing this rule, with no features at all associated with the Aux:
S[Agr ?x] ->
NP[Agr ?x] Aux VP[Agr ?x]
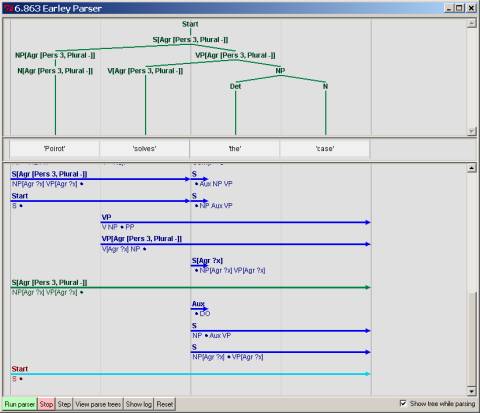
An example.
Let’s walk
through an example to see how feature checking works: Poirot solves the
case.
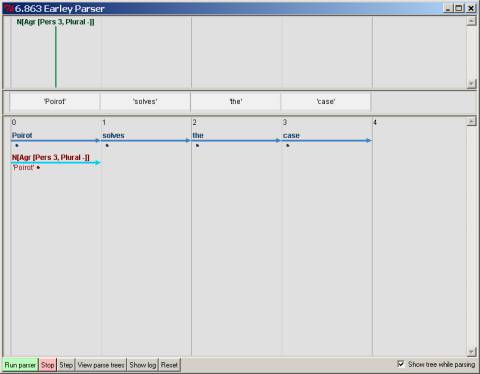
The first
snapshot below shows the first stage of agreement checking after the word Poirot
has been processed by scanning past the N.
Note that in virtue of the context-free rule with features NP[Agr
?x] ®
N[Agr ?x], the parser will look for a matching lexical
entry, and, in this case, find one. So,
all the features of Poirot from its lexical entry have been
percolated to the Noun, with ?x now bound to [Pers 3, Plural -]:
Continuing
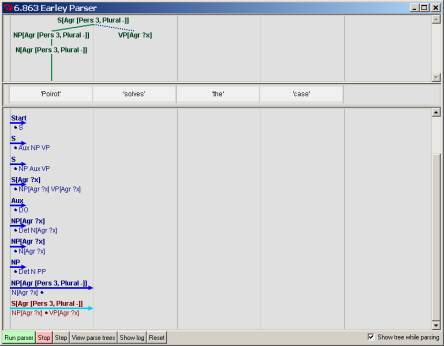
with the rule NP[Agr ?x] ® N[Agr ?x], this binding for ?x also fixes the value for the variable ?x in the NP, since this variable must also
have these same value. The features on
the NP are thus automatically coerced to this value, as shown when the N completes
the NP in the Earley parse. Accordingly, the parser shows the ‘dot’ being moved
over the NP in the expansion rule for S. Importantly, note that at this time,
since ?x has now been set, the parser can also assign this variable value as the feature values
associated with S:
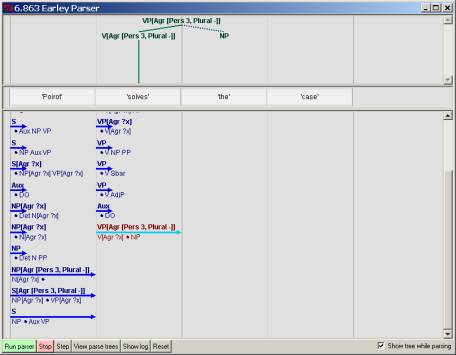
Continuing,
the parser will next predict the VP portion of the S rule. Since the VP starts out with a verb, also
with features, as with the N, these features are eventually percolated up by
feature agreement from the V’s lexical entry to the VP (we might also arguably
set the VP values via the value now set at the S node, but we put to one side
this possibility):
.
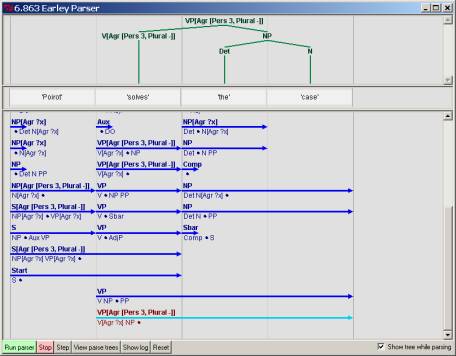
With the VP
complete, the full S rule is now checked for consistency of the ?x
variable
assignment. In this case, both the
subject NP and the VP have consistent feature values, so the assignment is
consistent. The parser can therefore
assign this value, [Pers 3, Plural -], to be the value also associated with the
S, as shown in the figure below. This
is the final output of the parser.
To implement
the feature extension in the Earley parser, note that the edges in the chart
must now be annotated with feature-value labels. Clearly, two edges are now distinct if they have different
feature value labels. Once a feature value is set, we can advance the ‘dot’ if
we actually find an edge (phrase) with the ascribed feature values in the
input. So, the essential part that
changes is when the dot can be advanced in a rule (when the Fundamental Rule
can apply), and how we distinguish different edges in the chart (they must have
consistent feature values in addition to consistent phrase names). You might want to think a bit about how far these
new distinctions would expand the chart size beyond its usual quadratic size
(in the length of the input). You
might also want to think about what would happen if feature structures were themselves
arbitrarily recursive, rather than just finite lists.
2.5.2
Your
assignment for this section.
Now that we
have seen how features are implemented in our Earley parser, please reconsider your
grammar from the previous section that implemented subject-verb agreement. We’d like you to reimplement that grammar
using the feature machinery described above.
Here are the sentences you were to handle. Your feature grammar should
correctly parse (and correctly reject) the sentences as shown:
1.
The solution solves the case
2.
* The
solution solve the case
3.
The
solutions solve the case
4.
* The
solutions solves the case
5.
The
solutions that Poirot sent to the police solve the case
6.
*The
solutions that Poirot sent to the police solves the case
Now we shall
calculate the size of your feature grammar to an equivalent context-free
grammar.
First you
should calculate the grammar size of your feature grammar – the total number of
symbols it takes to write the grammar down.
You should figure out a reasonable method to calculate feature ‘sizes’. Then, compare this value to that for your
equivalent context-free grammar and record the percentage size difference –
which is larger?
This small
example might not reveal very much, so let’s extend the result a bit. Assume
there the size of the feature grammar you are analyzing would be |G| without
features taken into account. Suppose
there are m agreement phenomena in a language, and each feature is
binary-valued. In terms of |G| and m,
what would be the maximum size of the nonterminal-expanded context-free
grammar |G’| that would be needed to encode m agreement
phenomena? What about the size of the equivalent
feature grammar? Call this value GF.
What is the value of GF/G’? What is the value of this as m®¥?
Hand in for your lab report: (1) Your feature grammar that reproduces
the agreement results from the previous section, along with output supporting your
results; (2) Your calculation of comparative grammar sizes for this simple
example, along with an explanation of the measure you adopted for calculating
feature grammar sizes; and (3) the results of your grammar size comparisons for
the general case of m features, including the comparisons between
ordinary and feature agreement context-free grammars.
[You may
skip the next section and go on to 2.6 if you so desire]
2.5.3
Agreement grammars – a formal account. More formally, let us define this kind of system as an agreement
grammar, by the extending the usual notion of a context-free grammar and
the notion of a derivation in a context-free grammar as follows. Then we shall see how to write rules in this
kind of grammatical system in a modified Earley parser. Your job will then be to re-do the grammar
from the previous section using agreement features.
Let’s define
the set of nonterminals and the notion of derivation in a context-free grammar
to get agreement grammars in the following way. The set of nonterminals
in an agreement grammar is characterized by a specification triple <F,
a, p> where:
·
F is a finite set of feature names;
·
A is a finite set of permissible feature
values;
·
p is a function from feature names to
permissible feature values. That is,
p: F® 2A
(the power set of A)
We say that
this triple specifies a finite set Vn of nonterminals, where a nonterminal may
be also thought of as a partial function from feature names to feature values:
Vn = {C Î A(F) :
" f Î domain(C)[C(f) Î p(f)] }
where YX is
the set of all partial functions from X to Y. Domain(C) is
the domain of C, the set {x: $y[<x, y>Î C]}.
Example.
Informally, in English we have agreement in number (singular or plural),
and ‘person’ (first, second third).
Let’s formalize this. Suppose we
have the feature names {PLURAL, PERSON}.
Then we have the following function p defined as follows, which
just says there is a PLURAL feature with values +, - (i.e., plural and
singular) and a PERSON feature, with values 1, 2, or 3.
p(PLURAL)
= {+, -}
p(PERSON)= {1, 2, 3}
Now we must
alter the ‘derives’ relation in an ordinary context-free grammar to handle the
‘matching’ part of feature agreement.
We say that
a category C' extends a category C (written C’
Ê
C) iff for all f in
Domain(C), [C’(f)= C(f)], that is , C' is a superset of C.
For example, the category {[PERSON 1], [NUMBER 1]} extends the category
{[PERSON 1]}.
Now we can define our system. An agreement grammar is a 5-tuple,
G = <<F, A, p>,
VT, FA, P, S>
whose first element specifies a set VN of syntactic categories
with features (nonterminals) and VT is a finite terminal alphabet (parts of speech or actual
words). FA is the set of agreement
feature names, FAÍ F. S is the distinguished starting symbol, SÎ VN . P is a finite set
of the usual context-free rule productions, each member taking one of the
following two forms:
1.
C ® a, where CÎ VN and a Î VT
2.
C0 ® C1 … Cn where
each Ci Î VN
To complete
the definition, we modify the derives relation to incorporate agreement.
We say that a production C’0 ® C’1 … C’n extends a production C0 ® C1 … Cn iff
each category C’i extends Ci, for every i, and a left-hand side nonterminal’s (mother’s)
agreement features appear on every daughter (right-hand side nonterminal):
a. "i, 0 £ i £ n, C'i extends Ci ; and
b. [the agreement convention]
"f Î (DOMAIN(C'0) ÇFA), "i, 1£i £n, [(f Î ( DOMAIN (C'i )) & (C'i (f) = C'0 (f)]
The second condition
ensures that all agreement features on the left-hand side of a production rule
are also found on all the right-hand side daughters.
We may now define the language generated by an agreement grammar.
If P contains a production A®g with an extension A' ®g ', then for any a,b Î(Vn ÈVT)*, we write aA'b Þ aA'b. Let Þ* be the reflexive, transitive closure of Þ in the given grammar. (That is, zero or more applications of
Þ.) The language L(G) generated by G contains
all the terminal strings that can be derived from any extension of the start
category:
L(G)= {x:
x ÎVT *
and $S', [S'ÊS & S' Þ* x]}
2.6
Grammar
6: Filler-gap dependencies and features
We can use
features to encode the atomic nonterminal names like S-WhNP used to track the
relationship between ‘wh’ fillers and gaps.
In this section, your assignment is to build a feature grammar that can
do this. Here is what you must do.
2.6.1 Features.
Consider a pair of
rules, one with ‘ordinary’ nonterminals and one with corresponding augmented
counterparts, as stated previously in section 2.3:
S ®
NP VP
S-WhNP ® NP
VP-WhNP
Instead of
creating new nonterminal names, S-WhNP, V-WhNP, etc., we could also approach the
problem in another way. Let’s think of
the S as having the feature WhNP or not – values + and –. In the first
rule above, the S does not have the WhNP feature, e.g., the
feature-value combination associated with the S is [WhNP
+]. In the second rule, both
S and VP have the feature-value [WhNP +]. Ultimately, as usual, this feature value is ‘passed up’ from the
lexical entry for which when followed by words that form an NP, so that
the NP is itself labeled [WhNP +]. You can see that now the rule with S-WhNP
and VP-WhNP can be replaced by simply adding a new feature-value
consistency check, in this case, one for WhNP.
As before, we will also need to add an new NP expansion rule to account
for the possibility of an ‘empty’ NP, so we need an NP rule that will expand to
the empty string, if the WhNP feature value is +. (Note that we have not described all the rules that will
need WhNP features – you should go back and see how your previous grammar was
implemented.)
Given this
new outlook on life, please rewrite your grammar from section 2.3 so that it uses
feature-value pairs as described, instead of new nonterminal names, to parse
the same wh question examples (and reject the wrong ones), from section
2.3:
1.
Which case
did Poirot solve
2.
Who solved
the case
3.
Which
solution did Poirot send to the police
4.
Which
detectives solved the case
5.
Which
solution did Poirot believe that the detectives sent to the police
6.
*Which
solution did Poirot send the gun to the police
7.
*Who solved
Please save
your grammar and the output showing that you can successfully parse (and
reject) these sentences, using features, to turn in for the end of this
section.
2.6.2 Other
sentence types with ‘wh’ features
We are far
from having exhausted the sentence types that display ‘displaced’ phrases, even
if we limit ourselves to sentences that are ‘wh’ questions. Let’s consider just one more:
To whom did Poirot send the solutions
This is a
lot like the sentences in the previous section, except the displaced ‘filler’
is a Prepositional Phrase, to whom.
Otherwise, it’s the same: there is a ‘gap’ after solutions where the
PP argument to the verb usually goes.
Your job is to add new rules, using features, to parse this example.
This can be done in an elegant way by seeing what the displaced wh-NPs and PPs
have in common. Hint: you might want to
consider a feature [wh +/-], denoting whether any word, phrase, etc. has
the feature +/- wh,
i.e., is a phrase that is
marked as containing a ‘wh’ word like which, what, etc. somewhere below.
2.6.3 The ‘slash’
feature
But wait,
there’s more! We can generalize (and
should generalize) this account of fillers-and gaps. Recall that in addition to
wh-phrases, one can also ‘displace’ almost any kind of phrase – e.g., Prepositional Phrases, as in To
the police Poirot sent the solutions
(not very pretty, but OK). As
before, there is a ‘gap’ after solutions – the object of the sentence, the
PP to the police, has been displaced to the front to serve as a topic
for semantic focus. So once again we
have a filler-gap structure, but it’s not a WhNP. We could use our new
feature machinery to handle this too – we could add a [PP
+] feature to indicate
that there’s a displaced PP somewhere underneath a particular node, just as S[WhNP +] means that this is a sentence from which we’ve displaced a
WhNP. Analogously, [PP -] denotes an ‘ordinary’ phrase – one where
there is no such displaced PP. So for
example, some of the rules to derive a sentence such as To the police Poirot
sent the solutions could be as follows:
S[PP +] ®
NP VP[PP +]
PP[PP
+] ®
P NP[PP +]
Of course,
we’d need more rules – at least, a rule to expand NP to an empty string in the
proper feature context, as before, plus others. (You should think about the
other rules we would need – but you don’t have to write them down.)
This is
quite inelegant – we again wind up duplicating all the features for all the
different kinds of phrases. We can
displace Adjective Phrases (AP), Verb Phrases, Sentences, etc:
Happier than the police, Poirot
will never be___ (the ___ indicates
the ‘gap’)
Instead of doing
this for each phrase category, we can introduce a special feature name, called SLASH, but written, amazingly, as a slash: /
. The idea is that the / feature can take as values all the
possible kinds of displaced phrases – NP, WhNP, PP, VP, etc. If the feature is not present, then it’s just
an ordinary phrase. We can then write
the PP and WhNP displacement rules as follows:
S[/ WhNP] ®
NP VP[/ WhNP]
S[/ PP] ®
NP VP[/ PP] or to show
how other features are written with the slash:
S[fin +, /
WhNP] ® NP VP[fin +, / WhNP]
We won’t ask
you to rewrite your grammar using slash rules like this. (Whew.)
But we do want you to briefly describe the strengths and
weaknesses of using this slash feature implementation as opposed to the explicit
listing of individually displaced phrases, like PP, NP, S, etc. For instance, it looks like we won’t save
anything in terms of number of rules, or so it seems, since we still have
individual rules to expand out displaced WhNP, PP, etc. Is this so?
Please explain why or why not.
Hand in for your lab report: (1) Your feature grammar that parses (or
rejects) the whNP sentences 1-7 above; a feature grammar that can do all this,
plus parse the sentence To whom did Poirot send the solutions, using a
feature system that systematically unifies WhNPs and PPs; and (3) your discussion of the slash feature
machinery.