Rapid advances in low power micro-electronics means soon cameras,
processors, and power supplies will be cheap, reliable and plentiful.
Thus, it will soon be possible to build a complete, autonomous, vision
module (AVM) using only a few chips. Such a device will be able to
function autonomously for weeks at a time, sending information over
low bandwidth radio connections. With the addition of a small solar
array, an AVM might operate indefinitely. While we won't have the
luxury of putting an entire super computer worth of processing on
board an AVM, one can easily foresee having 1 GOPS -- about what a
good workstation has today.
Integrated with a steerable platform, AVM's can perform autonomous
surveillance and make critical visual observations from locations
which are simply too dangerous for personnel. But there is another,
perhaps more speculative, niche for extremely cheap
AVM's. A disposable AVM (dAVM) would be entirely solid-state
and have no moving parts. It would be the size of a grenade, a good
deal lighter, and just as tough. Dozens if not hundreds could be
dropped from planes, scattered throughout a field, or mounted on the
rear of every vehicle. A dAVM could act anywhere that an extra pair
of eyes might be useful: protecting a perimeter; in surveillance
operations; or directing fire. We envision such a collection of dAVMs
as a FOREST OF SENSORS, and we believe that developing the
capabilities to deploy and most importantly to process the data from
such a forest of sensors will revolutionize existing surveillance and
monitoring methods.
While we are interested in designing and creating dAVMs, we believe
that one can focus on their utilization independent of their
design and instantiation. Thus, one can posit the existence of such
dAVMs, and ask what activities are made possible by their
availability. Many scenarios involving surveillance require
monitoring of large amounts of imagery from many vantage points. In
short, significant manpower must be expended. Imagine instead, a
scenario where 100 dAVM's could be rapidly affixed to trees, rocks, or
other elements in an environment. Alternatively, imagine a suite of
dAVMs mounted on small drone aircraft. The dAVM's would work in
concert, dividing the task of observation automatically among
themselves. Together they would immediately identify gaps in the area
that can be observed and suggest placement of additional devices. The
forest could detect failures of individual units, and use the inherent
redundancy of multiple sensors to avoid failure of the ensemble. The
forest could use change detection in combination with focus
of attention methods to allocate resources to components most able to
use them. Given such a forest of small, cheap, robust sensors, a
large number of important surveillance tasks becomes feasible, including
perimeter patrol, visual mines and urban security.
Our technical focus will be a forest of stationary sensors, although extensions
are possible to deal with imagery captured from a moving
platform (e.g., an aerial reconnaisance vehicle), by treating the time
sequence of images as if from a spatially distributed set of
sensors.
In all of the scenarios of interest, it will be difficult to carefully place and
calibrate each dAVM. A dAVM must discover its position and its
relationship to other dAVM's. Executing geometric self-calibration
will enable coordination of the dAVMs to build approximate site
models. But the dAVMs must also cooperate in their observations of
moving objects. For example, one dAVM whose field of
view is the left half of a field must be sure not to add its troop
estimates to the dAVM whose field of view is the entire field. Some
version of GPS will be helpful here, but it will not solve the entire
problem. In order to work in concert, dAVM's will need more than
simple camera calibration, they will need a notion of activity
calibration.
Even with coordination between dAVMs, the job of monitoring
activity is not complete. Imagine dAVMs observing two different
villages: in one opposing forces march through a square; in another
civilians congregate. Detecting the difference is critical
in modern engagements, where losses and civilian casualties
must be kept to an absolute minimum. Many features differentiate
these scenarios: the uniforms, the weapons, the activity patterns.
The latter points to a critical missing component in surveillance, the
ability not just to detect basic units of activity but to
automatically interpret them. This is a difficult task
which is very different from the tasks of change detection and target
identification. Much of the success of target recognition has been
based on the elegant use of geometric models. Unfortunately, there
can be no static geometric model of a platoon walking through a wood,
the construction of a revetment, or the passing of a military convoy.
In fact, the fundamental question has been changed: target recognition
finds objects; what we need is activity recognition.
Technical approach:
Two major technological advances are necessary for the widespread
deployment of dAVM's. One: we will need techniques for seamlessly
fusing visual information observed at different times and from
different locations. Two: we will need a framework in which to
construct activity models so activity can be reliably and efficiently
detected. An activity model should provide the mechanism
both for fusing and interpreting the many available sources of sensory
information, i.e., surveillance and monitoring is not just a matter of
deploying many sensors. The huge increase in the amount of image data
could in principle overwhelm any advantage one obtains by increasing
the range of coverage of the sensors. To coordinate their
surveillance and monitoring, the dAVMs must:
self-calibrate both in space and in activity, i.e., the
forest of sensors must automatically determine where each camera is
with respect to the others, and then must coordinate the observation
of activities between the viewpoints, using sensors with optimal views
to disambiguate interpretations, to avoid occlusions, and to
coordinate monitoring tasks, i.e. to perform activity
calibration.
construct rough site models, i.e., they must use observed static
and dynamic cues to block out obstacles, to identify open space, and
to relate sightlines between sensors.
perform generic detection of objects of interest, i.e., they
must have methods for detecting people and vehicles, and their
subparts, independently of viewpoint and of class type. Thus,
we will create general vehicle detectors and people detectors, rather
than the more traditional detectors tuned to specific instances of
such objects.
perform detection based on dynamic properties as well as
spatial properties, that is, we will train detectors that match
dynamic patterns of motion as well as spatial shape.
learn to model coordinated patterns of activity amongst large
numbers of primitive elements, so as to perform activity recognition.
Military Relevance:
Perimeter Patrol: Protecting a temporary camp's perimeter
is a difficult enterprise. Patrols must be organized and a perimeter
established. If instead, we have a forest of sensors that have been
attached by troops to points on the perimeter, then the surveillance
and patrol can be heavily automated. Equipped with low light sensors,
each dAVM would detect motion and classify it (e.g.\ animal vs.\ vehicle).
If animal, further analysis about location
and type could be performed. When enemy incursion is detected,
sentries would be immediately advised of the situation. The dAVM's
would be so inexpensive that they need not be retrieved, but can
continue to observe and report activity throughout the engagement.
Visual Mines: Modern mines are unfortunately non-discriminatory.
They are willing to explode when triggered by enemy forces, by
civilians and by friendly forces. Imagine replacing explosive mines
with ``visual mines''. dAVM's could be placed along key lines of
passage, and equipped to trigger a burst of communication to remote
observer sites when human activity or vehicle activity is recorded in
the vicinity of the mine. This would enable a remote operator to
identify friend or foe based on the visual data relayed by the visual
mine, to alert nearby troops to investigate, or to coordinate with
nearby fire control centers. Note that this is not just a case of
placing motion detectors, since such simple systems are likely to
overwhelm the operator with tons of false positives. Visual mines
should have some ``intelligence'' so that they only alert the operator
when they detect instances of likely activity, based either on
training from the operator or on generic models of activity.
Urban Security: In urban surveillance and monitoring, a forest
of sensors will be able to: i) register different viewpoints and
create virtual displays of the facility or area; ii) track and
classify objects (people, cars, trucks, bags, etc.); iii) overlay
tracking information on a virtual display constructed from the
observations of multiple cameras; iv) learn standard behaviors of
objects; v) selectively store video. Low bandwidth tracking
information could be continually stored allowing the observer to query
the system about activities. ``What did the person who left this bag
do from 2 minutes before until 2 minutes after leaving it?'' ``Where
is that person currently?" ``Show me a video of that person."
Tracking information could be used to tag activities such as cars
speeding towards the facility, people climbing the perimeter walls,
and unusual loitering around the facility.
Progress to date:
Geometric self-calibration of a forest of dAVMs using static
and dynamic features.
Understanding a dynamically changing scene given data from scattered
sensors is a difficult instance of multiple camera self-calibration
for several reasons. Because the environment is non-rigid, we cannot
rely on traditional methods of correspondence-based calibration for
static scenes. Because the sensors may not be perfectly stable, we
cannot perform the calibration once and assume its correctness as time
progresses. Because the sensors may not have overlapping ranges, we
cannot use traditional image-matching techniques to obtain point
correspondences.
We are building a system that takes advantage of time-varying data
from multiple cameras to obtain point correspondences and perform
robust calibration. Our system tracks a moving object in the scene and
uses its location at every time step as a single point correspondence
among multiple cameras. At every time step, the system stochastically
samples the correspondences from the last N frames and recomputes
relationships among cameras. Since the system is continually
recalibrating itself, it responds to changes in sensor locations by
stabilizing after several frames.
Our system is built to function in the many typical scenes found in
surveillance and monitoring applications where object motion is
confined to be approximately planar so traditional methods that
require 3D point correspondences in general position will fail. We
use planar correspondences to compute plane homographies between
overlapping image pairs and then use the homographies to warp all the
images to a single reference image plane. The result is an "extended
image" at every time step, and the sequence of extended images
simulates a virtual video sequence which contains global information
about the multi-camera system, such as which parts of the world are
not viewed by a camera, what path a tracked object takes through the
extended scene, and what global activities are occurring in the
environment. In addition, we are experimenting with decomposing plane
homographies in order to constrain the possible locations of cameras
in the extended image.
The result of this stage is a method for coordinating imagery from
multiple cameras, by using tracked objects to solve for geometric
relationship between each of the cameras.
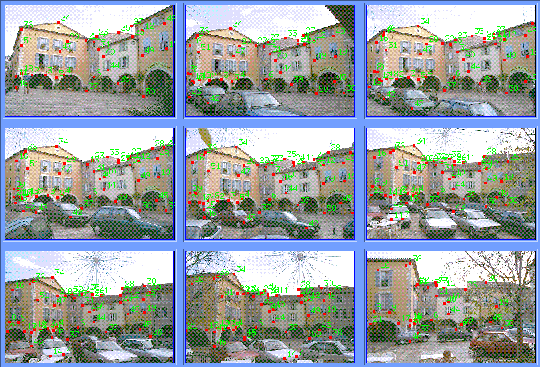
Shown above are three images taken of a scene with a moving object.
By automatically tracking and registering the objects, the relative
camera geometry is determined. This allows us to merge the views to a
single coherent framework, shown below.
Primitive detection of moving objects amongst a forest of dAVMs.
Our tracking system uses an adaptive backgrounding method to model the
appearance of the scene without any moving objects present. This model
approximates the recent RGB values of each pixel with a mixture of
Gaussians in the RGB colorspace. The particular Gaussian representing
the color which is more consistant and persistant is chosen as the
background model.
The pixels in the current image which are not within 2 standard
deviations of the background pixel model are assummed to be produced by
a moving object. Connected regions of these pixels are used to
approximate the position and size of the objects present in each frame.
A form of multiple hypothesis tracking is used to determine which
regions correspond from frame to frame and to filter regions which are
not persistant. The end result is the ability to continuously track
multiple discrete objects in an cluttered and changing environment.
The result of this stage is a robust tracking system that can track
multiple objects in real time, and acquire statistical data about each
tracked object.
Examples of tracking patterns are shown below. The left image shows
the observed area, the middle image shows the patterns of tracking,
with color encoding direction and intensity encoding speed, and the
right image is an overlay of the two. In each case, lanes of vehicle
traffic are easily identified, as are standard pedestrian lanes. In
the second example, note the large track in the lower right corner.
This is an outlier, corresponding to a truck backing into a loading
dock, in a region that normally sees only pedestrian traffic.
The following links provide a log dump of the tracking system running
continuously. Hourly dumps of a sample image, and the track
information for the past hour are provided:
Construction of simple site models from static features.
Once an initial calibration has been attained between the sensors,
this information can be used to convert the problem of coordinating
images into an n-camera stereo problem. If we can identify enough
corresponding features between pairs of cameras, this becomes an
epipolar computation, whose solution enables us to reconstruct the
scene. Such a reconstruction may not be complete, but it enables us
to block out major structures, thus enabling the system to reason
about occlusions, lines of sight, and to potential register detected
activities with static structures in the scene.
An example of the epipolar reconstruction. Shown at left are a set of
images, in the center are corresponding match points. Based on this,
the epipolar geometry between the cameras is automatically deduced.
This enables us to reconstruct a rough site model, as shown below.
An alternative method deals with reconstruction of extended scenes
from image sequences. In many cases, we can consider depth maps
reconstructed from small camera motions, but often these
reconstructions have two problems. First, certain areas are either
occluded or the surface is at such a sharp angle to the viewing
direction that the reconstruction is not accurate. Second, the
reconstructed scene is limited by the viewing angle of the camera and
we wish to perform reconstruction on more extended scene.
To deal with this, we have developed (jointly with Shashua at Hebrew
University) a method for direct estimation of structure and motion
from 3 views (Stein and Shashua CVPR 97). The key feature of that work
is that with three views one can directly estimate both structure and
motion from image gradients without having to find feature
correspondences or optical flow. Shown below are three images from a
sequence, plus the depth map recovered
for the image in the top left.
Along with the depth map we recover the camera motion. The figure
below shows a 3D rendering of the surface.
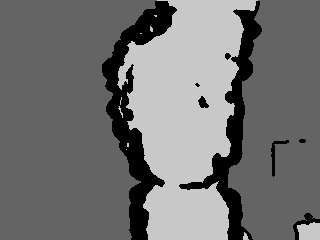
As a second stage we perform foreground background segmentation. We
also remove surfaces where the depth gradient is large (i.e. surfaces
that are at a sharp angle to the viewing direction) since these tend
to be occluding contours where surface reconstruction is not
reliable. The reconstruction works well on surfaces facing the camera
but along occluding contours the constant brightness constraint is
violated and one gets errors. So as a second stage we perform
foreground background segmentation using a K-means algorithm and also
remove surfaces where the depth gradient is high. This is shown
below.
The final stage is to combine reconstructions from multiple image
triplets into a single. For this we use the camera motion estimates
which allow us to transform all the surfaces into a common coordinate
frame. This leads to a more complete reconstruction. Shown below is
an example in which four surface reconstructions from different
viewing positions combined to form a more complete reconstruction. The
different colors indicate contributions from different
reconstructions.
The result of this stage is a method for constructing a rough site
model from multiple static views.
Refinement of simple site models using tracking of moving objects.
With the ability to calibrate multiple cameras, it will be possible to
construct spatial models of the environment. One reconstruction method
which can use the information we already have available is
reconstruction using accumulated line-of-sight. This method initially
models the space as completely occuppied. As objects move in the
environment, the regions of space between the camera and the visible
parts of the objects is removed from the model. This eventually creates
an efficient model of the areas where visible objects can move and where
they are occluded.
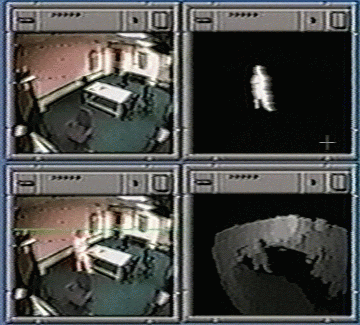
Shown below are examples of the system reconstructing a site. On the
left is a example for the processing, showing the base image, the
current image, and the extracted moving object. At the bottom right
is the current depth map built from tracking this person. On the
right is a reconstruction of the scene, with an image texture mapped
onto the detph reconstruction.
The result from this stage is a method for constructing rough site
models by tracking moving objects through the scene.
Prototype detectors for people and vehicles.
Many of the scenarios to which we intend to apply our monitoring
system will involve people and vehicles and the primary moving
objects. We need methods to classify tracked objects as belonging to
one of a small number of classes (people, cars, trucks, trains, etc.),
and then potentially to identify specific instances of class members
(which person, what kind of car, etc.). Simple methods for such
classification are based on using size and velocity information from
the tracked objects. These work surprisingly well, but require a
reasonable estimate of the ground plane relative to the cameras. This
information can either be obtained from the epipolar reconstruction,
or by simply tracking a moving object through the scene and using the
variation in size to determine the relative orientation of the ground plane.
More comprehensive detectors are also possible. We have extended
earlier work (funded by a DARPA/ONR MURI grant) in flexible template
classifiers to create people detectors and vehicle detectors. These
templates consist of sets of image regions, connected by flexible
springs to allow for spatial deformation. Relative photometric
relationships between the regions are used to constrain the templates
to detect specific classes of objects, while allowing for a wide range
of illumination and material type variation. We have constructed an
initial system for detecting vehicles, which is currently undergoing
evaluation. A corresponding method for detecting people is under
development.
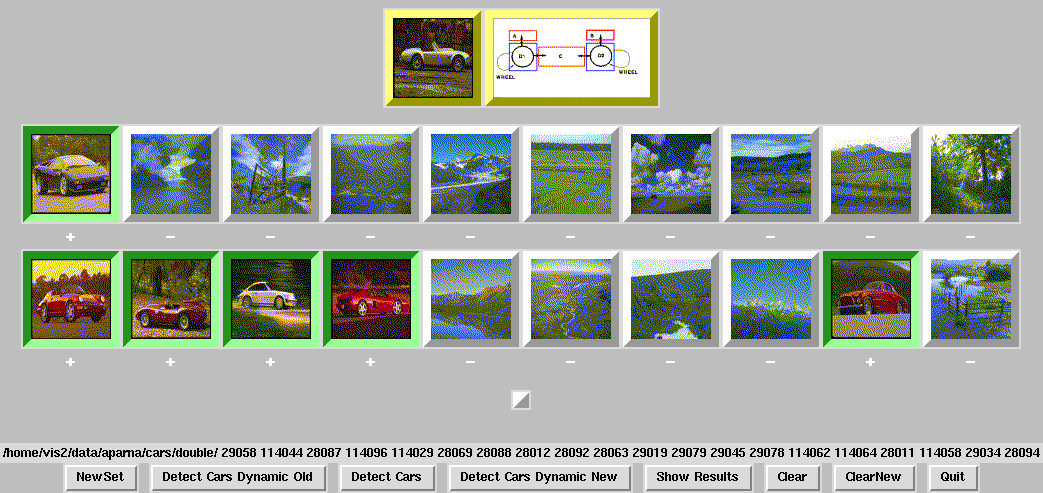
As an example, shown below are examples of using a vehicle template
detector (shown at the top of each image), together with results
classifying images containing a car or not. Notice that the only
error observed is a top view of a car, for which the present template
is insufficient.
All of the previous stages can be combined together to build rough
models of the site, and to detect moving objects in the site. To
identify particular objects, we can use the results of this stage,
which provides a method for detecting classes of objects from single
images.
Classification of primitive moving objects (e.g. people/animals/vehicles).
As noted above, we can use simple properties of tracked objects to classify
into categories. In testing, we have found that our tracking
system is sufficiently robust to enable a classification based on size
and velocity. This allows us to identify, track and count
pedestrians, cars, trains, and other vehicles. Such tracking can also
determine standard temporal patterns, e.g., what cycles of pedestrian
or vehicle traffic are most common? These patterns can then serve as
a basis for identifying unusual events, either because they occur in
places not normally associated with that event, or at times not
normally associated with that event.
Activity calibration of a forest of dAVMs, i.e., coordination of simple Motion monitoring amongst a set of sensors.
Our system is currently able to monitor scenes from a single camera in
real time, tracking moving objects and recording the associated track
information. By collecting statistics on the position, velocity, and
size of all moving objects, the system is able to create
representations of the activity patterns in the scene. These
statistics can then be automatically analyzed to identify common
patterns. We are presently exploring several alternatives for this
analysis, including a method that clusters track patterns using an
Expectation/Maximization algorithm to optimally assign individual
observations to clusters. This system is able to identify common
pedestrian paths, and vehicle paths. It is also able to isolate
unusual outliers, either based on spatial patterns or temporal ones
(e.g. a large vehicle driving in a region normally restricted to
pedestrian traffic).
Future plans
In the near term, we will build on our existing framework for
detecting, tracking and classifying activities, in a variety of
directions.
We will extend our tracking methods to incorporate multiple
cameras. This will require coordination between the cameras to
ensure that the same object is being tracked in each, as well as to
merge statistical information about the tracked object into a coherent
whole.
We will examine a set of possible techniques for classifying
basic activities from tracked data and associated image information.
These will include methods based on Expecatation/Maximation
clustering, Hidden Markov Models, Minimum Description Length
clustering, and possibly other trainable clustering methods. Basic
activities include identifying the type of tracked object (person,
vehicle, animal), and detecting instances of objects in scenes.
We will extend this set of techniques to classify complex
activities, such as interactions between objects, recognizing
particular instances of people or vehicles, and detecting common
activities between objects.
We will develop methods to integrate site models with activity
tracking. This will involve using the models to determine
interactions between tracked and static objects (e.g. when does a
person enter a building, does a person pick up a left object), to
determine automatic switching of viewpoints to keep the best camera
oriented on a tracked object, and to serve as feedback, i.e. to use
the detected motions to update and refine the site model.
We will integrate activity detection and classification with
recognition systems, to determine specific identities of tracked
people and vehicles.
We will continue to develop learning systems that can be applied
to the problem of classifying patterns of activity.
We will develop methods for spotting outliers in the statistical
patterns of activity. Such outliers are potential instances of
unusual events. We will incorporate recognition methods that further
classify such outliers into categories of unusual events.
Evaluation
Since this project is primarily aimed at demonstrating proof of
concept in the area of multicamera observation and coordination of
activity detection and classification, much of our effort will be
focused on creating methods to support novel capabilities. Some
aspects of this effort are amenable to more rigorous evaluation, and
we will execute such tests.
We will evaluate the selectivity of our flexible template
detectors at identifying instances of objects. We will test this by
determining false positive and false negative rates for detectors
applied to known databases of images, and by comparing human
classification of objects in video sequences.
We will statistically evaluate the performance of our tracking
system and our classification system, by having human observers scan
and classify randomly selected video sequences (e.g. how many vehicles
and people are observed and in what directions) and then comparing
these statistics to the system's performance.