|
|
|
|
CALO Perceptive Laptop Interface
As part of the DARPA CALO project led by SRI, the Vision Interface group at MIT CSAIL has developed a perceptive laptop interface to support meeting understanding, and for multimodal human-computer interface. We are developing algorithms to assess the conversational state of meeting participants or users of the CALO environment from a personalized device, such as a laptop or tablet computer. Our “ptablet” device is purely passive, and offers the following cues to conversation or interaction state: presence, attention, turn-taking, agreement and grounding gestures, emotion and expression cues and visual speech features.
More...
|
 |
|
CALO Perceptive Laptop Interface
|
|
|
|
|
|
Recognition and Retrieval with the Pyramid Match
Local image features have emerged as a powerful way to describe images of
objects and scenes. Their stability under variable image conditions is critical
for success in a wide range of recognition and retrieval applications. However,
comparing images represented by their collections of local features is
challenging, since each set may vary in cardinality and its elements lack a
meaningful ordering. Existing methods compare feature sets by searching for
explicit correspondences between their elements, which is too computationally
expensive in many realistic settings. In this work we develop efficient methods
for matching sets of local features, and we show how this matching may be used
as a robust measure of similarity to perform content-based image retrieval, as
well as a basis for learning object categories or inferring 3D pose. More...
|
 | --!>
|
|
|
|
|
|
|
Learning Task-Specific Similarity
A notion of similarity is central to many task in machine learning,
information retrieval and computer vision. Semantics of siilarity are
often determined by the specific task, and may not be captured well
with a standard metric approach. We develop a framework for learning
similarity, for the task at hand, from examples of what is and is not
considered similar.
More...
|
|
|
|
|
|
|
|
|
Fast example-based pose estimation
We develop Parameter-Sensitive Hashing (PSH):an algorithm for fast
similarity search for regression tasks, when the goal is to find examples in
the database which have values of some parameter(s) similar to those of the
query example, but the parameters can not be directly computed from the
examples. We apply PSH on the task of inferring the articulated body pose
from a single image of a person.
More...
|
|
|
|
|
|
|
|
|
WATSON:
Real-time Head Pose Estimation
Our
real-time object tracker uses range and appearance information
from a stereo camera to recover the 3D rotation and translation
of objects, or of the camera itself. The system can be connected
to a face detector and used as an accurate head tracker.
Additional supporting algorithms can improve the accuracy
of the tracker. More...
|
 |
|
Six-degree
of freedom head tracking with drift reduction.
|
|
|
|
|
|
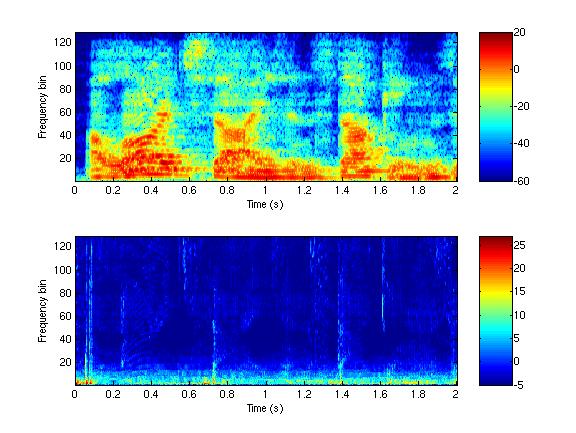
Learning Uncertainty Models for Audio Localization
We want computers to be able to localize sounds better. Human listeners
can successfully localize sounds in noisy and reverberant environments,
but computer systems can localize sounds well only in quiet, nearly
anechoic environments. One reason for this performance gap is that
human listeners exhibit the precedence effect, in which they weigh
localization cues from sound onsets more heavily when making
localization judgements. This effect has been well-studied in the
psychoacoustics literature but has not yet been integrated into a
practical computer system for audio localization. We formulate the
estimation of localization accuracy as a regression problem. Our
solution leads to improved audio source localization.
More...
|
 |
|
Learning the relationship between reverberant speech spectrograms and
localization uncertainty allows us to better combine localization
information across time and frequency.
|
|
|
|
|
|
Hidden Conditional Random Fields for Object Recognition
We model objects as flexible constellations of parts conditioned on local observations found by an interest operator. For each class the probability of a given assignment of model parts to local features is modeled by a Conditional Random Field (CRF). We propose an extension of the CRF framework that incorporates hidden variables and combines class conditional CRFs into a unified framework for part-based object recognition (hCRF). The main advantage of the proposed model is that it allows us to relax the assumption of conditional independence of the observed data (i.e. local features) often used in generative approaches.
More...
|
|
|
|
|
|
|
|
Information Extraction From Images And Captions
One of the main challenges in building a model that extracts semantic information from an image is that it might require a significant amount of labeled data. On the other hand extracting templates from captions might be an easier task that requires less training data. As a first step we propose to use a small training set of labeled captions to train a model that would map captions to templates. We will then use that model to label a larger set of images using their paired captions and use this larger dataset to train a visual classifier that maps images to templates.
More...
|
|
|
|
|
|
|
|
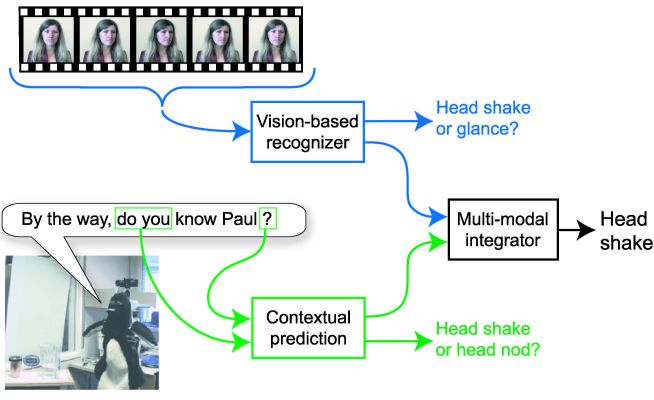
Contextual Recognition of Head Gestures
Head pose and gesture offer several key conversational grounding cues and are
used extensively in face-to-face interaction among people. We investigate how
dialog context from an embodied conversational agent (ECA) can improve visual
recognition of user gestures. We present a recognition framework which (1)
extracts contextual features from an ECA's dialog manager, (2) computes a
prediction of head nod and head shakes, and (3) integrates the contextual
predictions with the visual observation of a vision-based head gesture
recognizer. Using a discriminative approach to contextual prediction
and multi-modal integration, we were able to improve the performance of head
gesture detection even when the topic of the test set was significantly
different than the training set.
More...
|
 |
|
Contextual recognition of head gestures during face-to-face interaction with an embodied agent.
|
|
|
|
|
|
Hidden Condtional Random Fields for Gesture Recognition
Gesture sequences often have a complex underlying structure, and models that can incorporate hidden structure have proven in the past to be advantageous. Most existing approaches to gesture recognition with hidden state employ a Hidden Markov Model or suitable variant to model gesture streams; a significant limitation of these models is the requirement of conditional independence of observations. In addition, hidden states in a generative model are selected to maximize the likelihood of generating all examples of a given gesture class, which is not necessarily optimal for discriminating the gesture class against other gestures.
More...
|
 |
|
Arm Gesture Sequence superimposed with a 3D body tracker
|
|
|
|
|
|
IDeixis: Image-based Deixis for Finding Location-Based Information
IDexis project is to develop an image-based deixis for refering to a
remote location in applications of finding location-specific
information. IDexis is an image-based approach to finding
location-based information from camera-equipped mobile devices. It is
a point-by-photograph paradigm, where users can specify a location
simply by taking pictures. Our technique uses content-based image
retrieval methods to search the web or other databases for matching
images and their source pages to find relevant location-based
information. In contrast to conventional approaches to location
detection, this method can refer to distant locations and does not
require any physical infrastructure beyond mobile internet service.
More...
|
 |
|
|
|
|
|
|
|
Multimodal Co-training of Agreement Gesture Classifiers
In this work we investigate the use of multimodal semi-supervised learning to train a classifier which detects user agreement during a dialog with a robotic agent. Separate ‘views’ of the user’s agreement are given by head nods and keywords in the user’s speech. We develop a co-training algorithm for the gesture and speech classifiers to adapt each classifier to a particular user and increase recognition performance. Multimodal co-training allows user-adaptive models without labeled training data for that user. We evaluate our algorithm on a data set of subjects interacting with a robotic agent and demonstrate that co-training can be used to learn user-specific head nods and keywords to improve overall agreement recognition. More...
|
|
|
|
|
|
|
|
Face recognition from image sets
In most paradigms of face recognition it is assumed that while
a set of training images is available for each individual in the database,
the input (test data) consists of a single shot. However, in many scenarios
the recognition system has access to a set of face images of the person to
be recognized. We want to use this fact to do a better job in recognition. More...
|
 |
|
Matching distributions, rather than individual images or a single image to a set.
|
|
