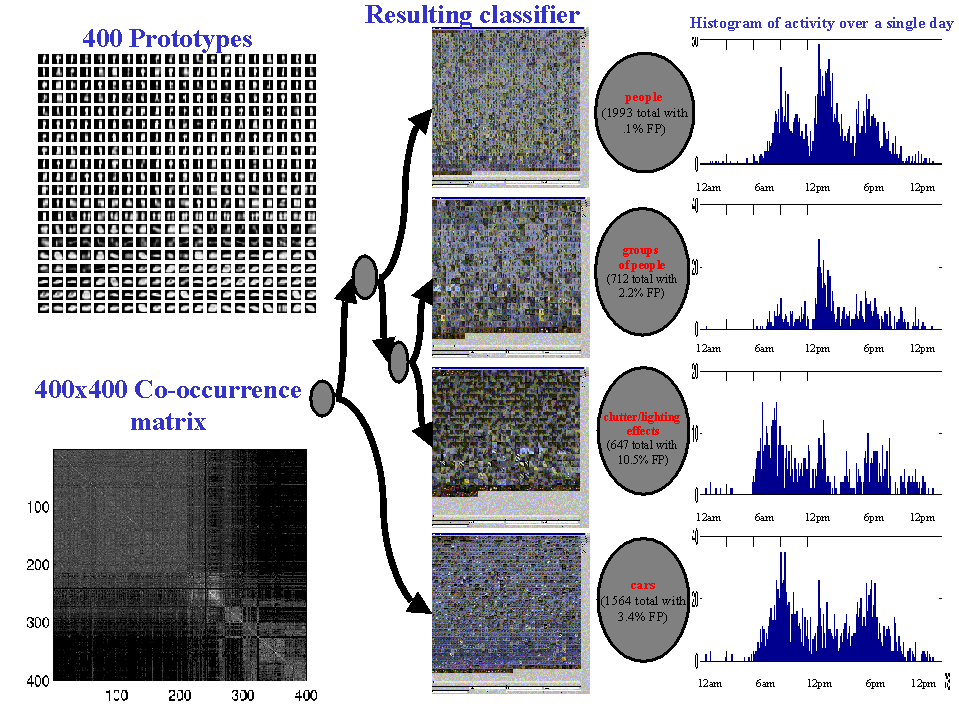
This web page shows some of our recent results in classification. The examples shown here include classification based on shape, color, and activity. They are posed as clustering, query retrieval, or anomoly detection problems. One of our goals of the project is to include all these characteristics and more to perform classification, query retrieval, user-defined interest flagging, and anolmoly detection.
Automatically classifying objects in one modality allows us to easily learn inter-relationships between modalities, to learn long-term patterns of activities in those clusters, and to pre-classify objects for quick retrieval. Creating an effective query retrieval system allows a user to ask the system about a particular interest which may not exactly correspond to one of the clusters automatically generated. Anomoly detection allows us to flag "interesting" events without extensive user interaction.
We would like our system to be capable of classifying an object given only the instantaneous motion silhouette of the object without supervision. While this seems like a lofty goal, we can use our tracking sequences to learn some invariance on our space of silhouettes. As a person walks or an automobile drives through a scene, it presents differently at each frame. We attempt to use the invariance shown within the tracks to give us information about how to cluster the represenations.
In our current domain, we are able to find two very discrete clusters of motion silhouettes... one pertaining to cars and one pertaining to people. Using those automatically generated clusters, we have taken all the activity in a scene for a particular morning and seperated it into two seperate TrackApplets. While this classification is simple, it can reduce your query domain size by one half in many cases.
A simple example shows how the shape of the silhouette of the object can be used to automatically find two seperate classes: cars vs. people.
This example uses the position, movement, and size characteristics of the objects over time to cluster based on the activity of the object. It also clusters based on idenity in certain cases.
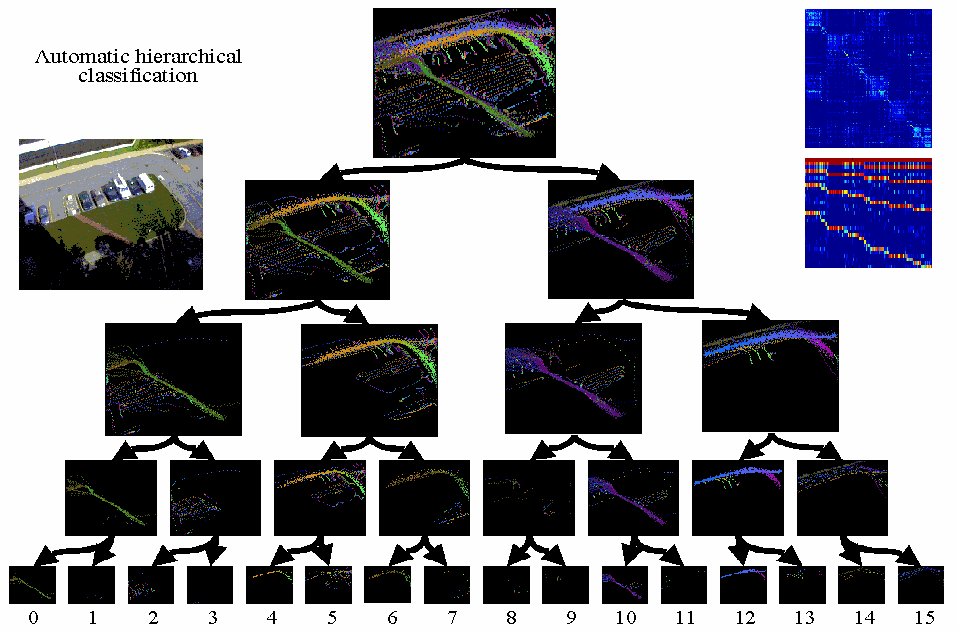
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
Above is a binary tree which shows how the activities for the scene (shown in the upper left) have been automatically broken down. At the top of the tree is the "universal" event. Every event is shown in the corresponding template. The first break is based on direction (eastbound vs. westbound). While this may seem like an obvious break to make, it only made it because very few objects showed both eastbound and westbound characteristics. This is not the case in many scenes.
The second break (on both sides of the tree) seperates path traffic from road traffic. Further breaks break activities down into very tight clusters of activities. If you click on any of the numbers below the tree you will be able to view the activities of the corresponding leaf node in a Java 1.1 Applet.
One of the easier methods of interacting with our system is selecting a number of objects which exhibit the characteristics you are interested in and allowing the system to find similar ones. Our first example is two queries made on a particular cluster of activity from above. One was a red cars and one was white cars. The both contain the same cars, just in different order.
Below is an example where the query was a biker on the road in the upper left. The first 14 responses were bikers on the same side of the road. They were followed by some other pedestrians and finally cars moving similarly in the same area.

Activities which are repeatative in a certain scene can be clustered together, but classifying activities which are have no similarity to statistically significant clusters is often meaningless. When such unusual activities occur, it is useful to notify the human observer and allow him to make a judgement about whether it is interesting. Some examples of outliers someone may find interesting are:
Below is an example of outlier detection. It shows the top fifteen most unusual activities of almost 1000. Most of the 1000 tracks were cars and pedestrians on the road and sidewalk. While three cars remained low on the list, it found two semi trucks and two bicyclist unusual because they appeared in an area where cars were almost exclusive.

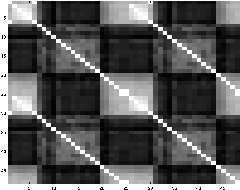
Some activities are not unusual in a certain context, but are unusual in another context. Some examples are: deliveries in the morning vs deliveries after midnight; a car moving through an intersection on a green light vs. on a red light; etc. As in all our past work, we would like to find these contexts automatically. Below is a graph of similarity between one hour block of activity for 48 hours. It is not hard to imagine learning that there is a 24 hour cycle.