A Forest of Sensors

|
| A Forest of Sensors |
|
| Organization: | Massachusetts Institute of Technology |
|---|---|
| Department: | Artificial Intelligence Lab |
| Principal Investigators: |
Eric Grimson |
| Other Investigators: |
Chris Stauffer Gideon Stein Raquel Romano Lily Lee Paul Viola Olivier Faugeras |
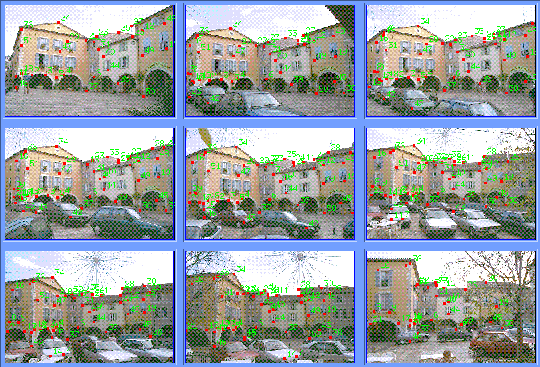
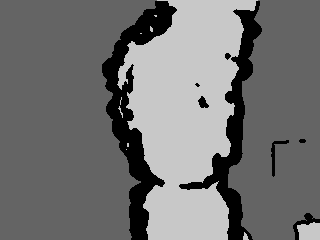
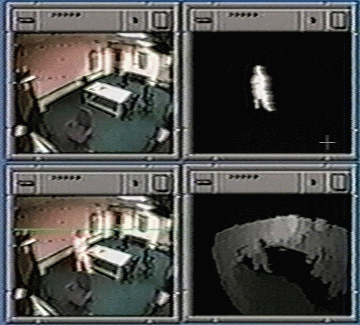
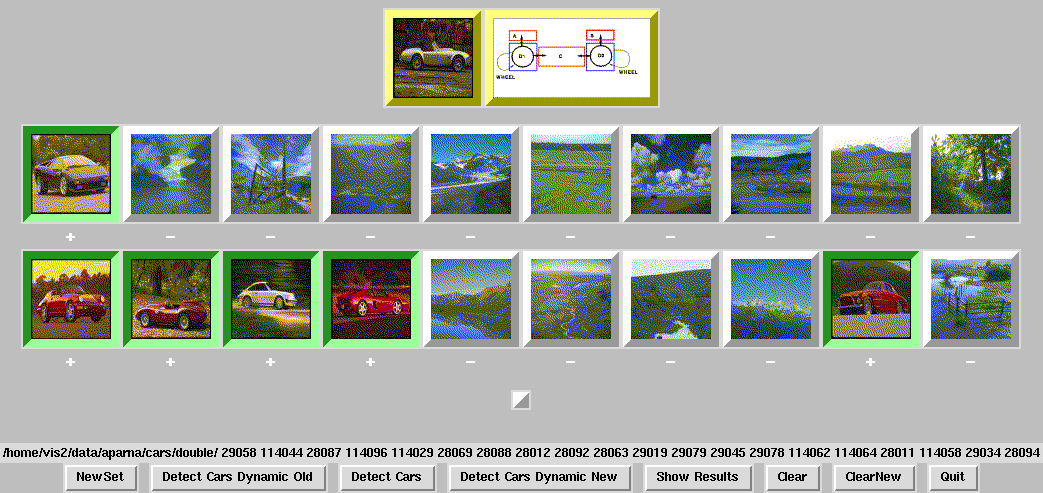
| Technical Area: | Video Surveillance and Monitoring (VSAM) |
| Related Pages: | A Forest of Sensors: Recent Results |

|

|

|

|

|

|

|

|

|

|

|
|

|

|

|

|

|

|

|
|

|
|

|

|
|