



A traditional optimizing compiler relies entirely on static analysis of the program's source code. The kinds and scope of static analyses which can be practically undertaken have increased dramatically in the last decade. The more sophisticated understanding has made possible more extensive program transformations which have proven their worth in the increased performance of programs, e.g., when benchmarks and real world programs run noticeably faster on the same computing platform solely due to an improved release of a vendor's compiler. However, static analysis by definition can only guess at the performance characteristics of a program. Trying to ascertain the true run-time characteristics of a program would effectively require the compiler to emulate the target architecture and hardware/software run-time environment to simulate running the program --- and despite vast improvements in emulation technology, emulation is still relatively impractical. Furthermore, there would still be the problem of not having the typical usage input data sets for the program available.
Does it matter that static analyses only give the compiler an incomplete understanding of the program? It can; certain kinds of speculative transformations are not performed or even considered either because they don't always improve performance and may even sometimes worsen performance, or because they may cost more in space overhead than can generally be justified --- examples include inlining and loop unrolling, techniques which currently are only used by agressive optimizing compilers, but only in a very restricted fashion. However, with run-time profiling feedback, a smart compiler [] can try out these more speculative transformations and ascertain which appear to be beneficial in a particular instance. In short, a smart compiler can run experiments.
Ideally, a smart compiler would take normal source code, written by a programmer who gave no thought whatsoever to quasistatic computing issues, use profiling feedback to determine what parts of the program are ``hot'' and are therefore interesting loci, and automatically analyze those parts of the program for potential radical transformations. However, we need stepping stones on the way to that eventual goal: one such stepping stone which has been proposed is a clever compiler. A clever compiler relies on programmer annotations in the source code to help it decide how to organize and analyze profiling feedback gathered at program run-time; it is also up to the programmer to indicate potential transformations by encoding alternative code sequences with the annotations. Thus, a clever compiler can still quasistatically choose between the programmer-indicated alternative code implementations, but falls short of a smart compiler in that it cannot create alternative implementations through its own semantic analysis of source code.
Figure: Automating the profiling feedback loop.
Although taking advantage of a clever compiler requires some
additional programmer effort, it should still be much easier than the
traditional manual performance optimization process, and retains
the quasistatic computing advantage that the program will dynamically
evolve in response to changing usage patterns and changing computing
platforms without continuing programmer effort.
Figure
and retains
the quasistatic computing advantage that the program will dynamically
evolve in response to changing usage patterns and changing computing
platforms without continuing programmer effort.
Figure 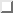 illustrates the difference in the
feedback loop between a programmer using a traditional compiler and a
programmer using a smart compiler. Note that the programmer using the
smart compiler is not involved in the iterative loop. Substituting a
clever compiler for a smart compiler, the programmer would not be
involved in the iterative loop, although there might be an extra step
for the programmer to annotate the source code for the clever compiler
to work with.
illustrates the difference in the
feedback loop between a programmer using a traditional compiler and a
programmer using a smart compiler. Note that the programmer using the
smart compiler is not involved in the iterative loop. Substituting a
clever compiler for a smart compiler, the programmer would not be
involved in the iterative loop, although there might be an extra step
for the programmer to annotate the source code for the clever compiler
to work with.
Figure also shows that it is important that the
profiling mechanisms used by quasistatic computing be very
light-weight in nature, since the end-user is always using
an instrumented executable. A number of different mechanisms to
gather profiling data exist (e.g., prof, gprof,
pixie), with overheads ranging from 3--5% to 40--200%. While a
programmer who is explicitly running test cases is usually willing to
tolerate that kind of slow-down, an end-user would be unhappy.
Admittedly, after a period of time of sustained experimentation, the
smart compiler can conclude it has likely converged on a near-optimal
program, and reduce the frequency and level of instrumentation and
experimentation, thus reducing overhead to near zero. However, it is
still necessary to keep overhead low even during that experimental
phase. Regardless of the particular mechanism used, a smart compiler
should be able to substantially reduce the profiling overhead, since
it is only interested in gathering performance statistics
relevant to the particular experiments it is conducting at any given
time, and not detailed statistics about all parts of the program.