Now that the process of information access in electronic environments has been posed as navigation through some type of space, it can be asked how well the commonly used information spaces mentioned in the introduction support the process of information navigation. The basic assumptions about information-seeking outlined above can be rephrased as a set of questions that can be asked about any information space:
We hope to show that although the basic techniques for information organization provide some of the features necessary for successful information-seeking, they do not inherently provide the affordances needed for navigation through an information space. Some of those affordances include landmarks, memorable locations with special significance; well-structured paths; and maps, survey representations of the space. The solution, then, is to design information spaces that employ these affordances to assist the information-seeker in his task.
Hierarchical classifications are used in such diverse applications as library subject classification [Immroth, 1980], Internet newsgroup hierarchies, and directories of sites on the World Wide Web (e.g., [Yahoo Incorporated, 1998]). In a hierarchical classification, a set of labeled nodes are arranged into a tree. The label given to a node indicates an attribute shared by the items of information attached to that node, and all of the node's children. Each node defines a category that proceed from the general (has fewer attributes) at the root to the specific (has more attributes).
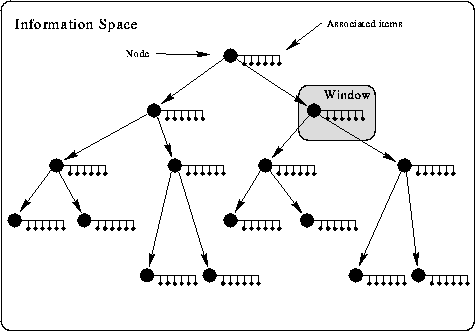
As an information space, a hierarchical classification looks like Figure 2-1. The information-seeker's window shows the current node and the items of information attached to it. Two kinds of moves in the hierarchy are available from this location. The seeker can move the window to the parent of the current node, corresponding to a move to a more general category (in that its label applies to a larger number of descendants), or to one of its children, a move to a more specific category. Or, the seeker can examine an item of information at the current node in more detail.
At each node, the seeker must decide whether the information needed is available at the present node, or if a move should be made up or down the hierarchy. Because seeking proceeds downward from the root node, a move up can be thought of as backtracking, debugging an incorrect choice made earlier in traversal - a difficult process, since every node already chosen has some relevance to the seeker's information need. The correction must take place at a sufficiently high position in the hierarchy to include the desired material in a subtree of the new node.
The choice of names for a node label is crucial, as it must indicate relevance for all of its descendants. Since combinations of binary attributes defined over a set induces a boolean lattice, a hierarchy must break this lattice at selected points. This means that cross-hierarchical links are required to supplement the tree structure of the hierarchy when categories do not strictly follow a subset relationship.
Obtaining a survey view of a hierarchy is also problematic. A breadth-first traversal of the hierarchy at a high level can communicate the topic structure of the content, but obtaining higher resolution surveys requires viewing an exponentially increasing number of nodes. Pictorial representations of hierarchies are possible, [Robertson et al., 1991], but the same exponential increase with depth presents special difficulties for visualization [Carrière and Kazman, 1995]. Multiple traversals through the space will also gradually increase the number of nodes seen by the information-seeker, but a large proportion of the space will remain unseen. Landmarks, memorable locations that provide cues for orientation, are also not an inherent part of a hierarchy.
Hierarchies are well-suited for needs which can be fulfilled by narrowing down a from a general category of material to a more specific one, and one in which the category of the right specificity can be readily identified, so the seeker knows when to stop movement. Hierarchies, then, trade off the ability to reach any node by a potentially short path from the root with the risk of a wrong move requiring backtracking.
Full-text indexing makes the entire text content of documents available for term searching. The results of a search are an ordered list of documents, ranked by a measure based on the number of occurences of query terms in the text of each document. Documents with more occurences are ranked higher and presented first. Algorithms and implementations of full-text indexing are well-studied and well-represented in the literature (see, for example, [Frakes and Baeza-Yates, 1992] and [Jones and Willett, 1997]).
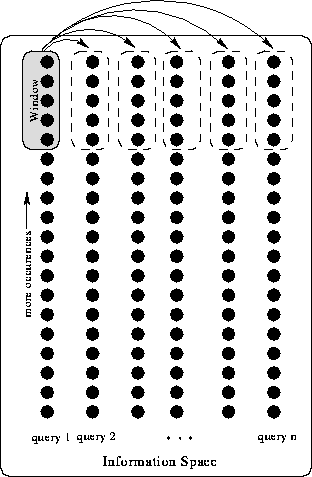
The type of information space created by full-text indexing system appears in Figure 2-2. The window shows the top-ranked documents found by the search system, according to the terms entered by the user. Each row in the space represents an ordering on the documents induced by a particular set of query terms.
The first move in such a space is the formulation of a new query to the system. Subsequent moves may refine the initial query by adding or removing terms, or begin afresh with an entirely new set of terms. The present location in the space is identified implicitly by the specific terms chosen for the current query and explicitly by the top documents returned by the system. When first beginning an information-seeking episode, the user must solve the difficult problem of query formulation - selecting terms likely to be in documents of interest, but unlikely to be found elsewhere. Given that combinations all of possible terms in the document corpus are available as moves, finding where to begin in this space is a challenging task.
Once an initial query has been formulated, giving the user an initial location in the space, modifying that query corresponds to moving to a new location in the space. Again, the same problem arises: the system itself gives little guidance on which terms to modify, relying on the user to find a useful move among the many available queries. Mapping the space is not possible by simply looking at the results of a number of queries. It is difficult to compose them into an overall picture relating the topic structure of the underlying corpus. The size, scope, and domain of the collection are difficult to infer from query results, and the user cannot relate a result as typical or representative of the entire collection. Landmarks are also not available in such a system.
Although a full-text indexing and search system is a powerful tool for information access, its limitations lie in the unstructured way it represents the underlying corpus. It relies on the user to find an initial combination of query terms that corresponds to his information need. Once formulated, every location in the space is immediately available, and the user must decide which of the many moves in this space are useful and which are not.
A hypertext system, as originally proposed by Vannevar Bush [Bush, 1945], is a way to link documents to form ``associative trails'' which could be named and stored for later recall and duplication. In practice today, the use of hypertext bears little resemblance to Bush's proposal. Instead of links encoding lines of reasoning or associations, they now serve many additional roles. In effect, following a link is now a content-free user interface action whose semantics must always be recovered from the link's context. The meaning of moves in this space are therefore nonuniform; they depend crucially on the user's location in the hypertext.
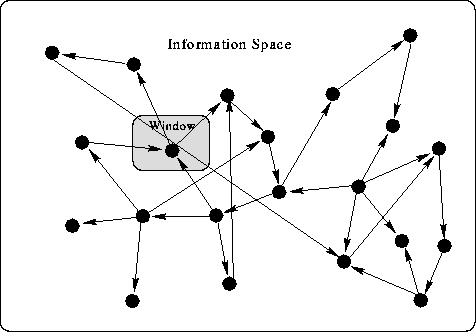
An information space for a hypertext looks like Figure 2-3.
The view through a window in this space is one node or document in the hypertext and the anchors denoting outgoing links. The overall topology of the hypertext is not apparent from this localized view, and ambiguous link semantics make the formation of a meaningful spatial representation problematic. In addition, arbitrary directed graphs cannot be drawn in a fixed-dimensional space without links overlapping, making the mapping of hypertext difficult.
Paths through hypertext lack explicit context and consistent meaning: the user can make large semantic jumps by taking a small step syntactically. Again, the basic elements required for effective wayfinding - landmarks, meaningful paths, survey representations - are not required in the hypertext model. All these factors interfere with navigation through hypertext, and lead to what is called being ``lost in hyperspace:'' the user not knowing where to go next, knowing where to go but not knowing how to get there, or not knowing where he is in relation to the overall hypertext [Elm and Woods, 1985,Edwards and Hardman, 1993].
Given that current information structuring techniques do not inherently incorporate all the affordances needed for orientation, navigation, and mapping, we need to design our information access environments to support these abilities explicitly. This is the core of what an information space is: a design commitment to environments that humans can use to navigate in the same way that they can navigate in the real world. Or:
KNOWLEDGE NAVIGATION. To enable successful navigation in a collection of information, design a principled information space that users can navigate to search, browse, learn, and interact.
To be effective, an information space should fulfill certain requirements to enable people to use their real-world navigation skills within it. These include:
An information space that fulfills these requirements can solve the problem of being lost in hyperspace. The user will always know his location relative to other information in the space and can effectively construct routes to search for the information he needs. The user can also browse through the space in a more undirected manner to look for information of interest, or take an instructive tour through the space that reveals the depth and breadth of its contents.
If an information space uses the same features that help us navigate in our physical environment, like landmarks, paths, and survey views, then the navigator can construct a spatial mental representation of it. The study of such cognitive or mental maps of physical spaces has concluded that multiple navigation experiences in the same environment allows individuals to estimate distances and directions to unseen objects, sketch maps of the area, and construct successful routes not used before [Siegel and White, 1975,Evans, 1980]. Also, access to survey views or maps of a space can enable wayfinding performance similar to that afforded by route-following experiences [Thorndyke and Hayes-Roth, 1982,Golledge et al., 1995].
These abilities have special meaning in an information space. If information access is navigation, then successful wayfinding enables the user to meet his information need. And, since the space is designed around a principle reflecting its content, his mental map is a conceptual map: a map of the ideas, concepts, and material within the space. Multiple wayfinding episodes will reinforce his conceptual map, improving his knowledge of the space and what it contains.
Information spaces do not need to be three-dimensional and Euclidian in nature, but should be constructed so that users can apply the navigation skills they use in the physical environment. The basic elements mentioned earlier - landmarks, paths, and maps - will each play an important role as features in these spaces. Since information organization methods are not navigable in the same way that our physical spaces are, we need to look outside of the electronic realm for examples of navigable information spaces. This motivates the study of one kind of physical information space: educational exhibits.