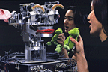- Detecting Head Orientation:
We have implemented and evaluated a system that
detects the orientation of a person's head from as far as six meters
away from the robot. To accomplish this, we have implemented a multi-stage
behavior. Whenever the robot sees an item of interest, it moves its
eyes and head to bring that object within the field of view of the foveal
cameras. A face finding algorithm based on skin color and shape is used
to identify faces and a software zoom is used to capture as much information
as possible. The system then identifies a set of facial features (eyes
and nose/mouth) and uses a model of human facial structure to identify
the orientation of the person's head.
Watch it in action (Quicktime movie):
This video clip demonstrates the simple ways that
Cog interprets the intentions of the instructor. Note that unlike the
other video clips, in this example, the instructor was given a specific
sequence of tasks to perform in front of the robot. The instructor was
asked to "get the robot's attention and then look over at the block".
Cog responds by first fixating the instructor and then shifting its
gaze to the block. The instructor was asked to again get the robot's
attention and then to reach slowly for the block. Cog looks back at
the instructor, observes the instructor moving toward the block, and
interprets that the instructor might want the block. Although Cog has
relatively little capabilities to assist the instructor in this case,
we programmed the robot to attempt to reach for any target that the
instructor became interested in. 
For more information see:
Brian Scassellati. "Foundations for a Theory of
Mind for a Humanoid Robot", Massachusetts Institute of Technology, Department
of Electrical Engineering and Computer Science, Cambridge, MA, PhD Thesis,
June 2001. 
[Back to Top]
- Mimicry:
Cog's torso was retrofitted with force sensing capabilities
in order to implement body motion via virtual spring force control.
In addition, we developed a representational language for humanoid motor
control inspired by the neurophysiological organizing principle of motor
primitives. Both endeavors allowed Cog to broadly mimic the motions
of a person with whom it interacts using its body or arms. In the arm
imitation behavior, the robot continuously tracks many object trajectories.
A trajectory is selected on the basis of animacy and the attentional
state of the instructor. Motion trajectories are then converted from
a visual representation to a motor representation which the robot can
execute.The performance of this mimicry response was evaluated with
naive human instructors.
Watch it in action (Quicktime movie):
A video clip of Cog's new force-control torso exhibiting
virtual spring behavior. The ability to use virtual spring control on
the torso allows for full body/arm integration and for safe human-robot
interaction.
This video clip shows an example of Cog mimicking
the movement of a person. The visual attention system directs the robot
to look and turn its head toward the person. Cog observes the movement
of the person's hand, recognizes that movement as an animate stimulus,
and responds by moving its own hand in a similar fashion.
We have also tested the performance of this mimicry
response with naive human instructors. In this case, the subject gives
the robot the American Sign Language gesture for "eat", which the robot
mimics back at the person. Note that the robot has no understanding
of the semantics of this gesture, it is merely mirroring the person's
action.
For more information see:
Aaron Edsinger. "A Gestural Language for a Humanoid
Robot", Massachusetts Institute of Technology, Department of Electrical
Engineering and Computer Science, Master's Thesis, Cambridge, MA, 2000.
Brian Scassellati. "Foundations for a Theory of
Mind for a Humanoid Robot", Massachusetts Institute of Technology, Department
of Electrical Engineering and Computer Science, Cambridge, MA, PhD Thesis,
June 2001.
[Back to Top]
- Distinguishing Animate from Inanimate:
We have implemented a system that distinguishes
between the movement patterns of animate objects from those of inanimate
objects. This system uses a multi-agent architecture to represent a
set of naive rules of physics that are drawn from experimental results
on human subjects. These naive rules represent the effects of gravity,
inertia, and other intuitive parts of Newtonian mechanics. We have evaluated
this system by comparing the results to human performance on classifying
the movement of point-light sources, and found the system to be more
than 85% accurate on a test suite of recorded real-world data.
Watch it in action (Quicktime movie):
Cog does not mimic every movement that it sees.
Two types of social cues are used to indicate which moving object out
of the many objects that the robot is tracking should be imitated. The
first criterion is that the object display self-propelled movement.
This eliminates objects that are either stationary or that are moving
in ways that are explained by naive rules of physics. In this video
clip, when the robot observes the ball moving down the ramp, Cog interprets
the movement as linear and following gravity and ignores the motion.
When the same stimulus moves against gravity and rolls uphill, the robot
becomes interested and mimics its movement.
For more information see:
Brian Scassellati. "Discriminating Animate from
Inanimate Visual Stimuli," to appear at the International Joint Conference
on Artificial Intelligence, Seattle, Washington, August 2001.
[Back to Top]
- Joint Reference:
Using its new 2-DOF hands that exploit series elastic
actuators and rapid prototyping technology, Cog demonstrated basic grasping
and gestures. The gestural ability was combined with models from human
development for establishing joint reference, that is, for the robot
to attend to the same object that an instructor is attending to. Objects
that are within the approximate attention range of the human instructor
are made more salient to the robot. Information from head orientation
is the primary cue of attention in the instructor.
Brian Scassellati. "Foundations for a Theory of
Mind for a Humanoid Robot", Massachusetts Institute of Technology, Department
of Electrical Engineering and Computer Science, Cambridge, MA, PhD Thesis,
June 2001.
Watch it in action (Quicktime movie):
This video clip demonstrates the simple ways that
Cog interprets the intentions of the instructor. Note that unlike the
other video clips, in this example, the instructor was given a specific
sequence of tasks to perform in front of the robot. The instructor was
asked to "get the robot's attention and then look over at the block".
Cog responds by first fixating the instructor and then shifting its
gaze to the block. The instructor was asked to again get the robot's
attention and then to reach slowly for the block. Cog looks back at
the instructor, observes the instructor moving toward the block, and
interprets that the instructor might want the block. Although Cog has
relatively little capabilities to assist the instructor in this case,
we programmed the robot to attempt to reach for any target that the
instructor became interested in.
For more information see:
Brian Scassellati. "Foundations for a Theory of
Mind for a Humanoid Robot", Massachusetts Institute of Technology, Department
of Electrical Engineering and Computer Science, Cambridge, MA, PhD Thesis,
June 2001.
[Back to Top]
- Simulated Musculature:
Cog's arm and body are controlled via simulated
muscle-like elements that span multiple joints and operate independently.
Muscle strength and fatigue over time are modulated by a biochemical
model. The muscle-like elements are inspired by real physiology and
allow Cog to move with dynamics that are more human-like than conventional
manipulator control.
For more information see:
Bryan Adams. "Learning Humanoid Arm Gestures". Working
Notes - AAAI Spring Symposium Series: Learning Grounded Representations,
Stanford, CA. March 26-28, 2001, pp. 1-3
[Back to Top]
Lazlo
- Attentional System Based on Space Variant
Vision:
Lazlo uses an attentional system based completely
on space variant (in particular log-polar) vision. This allowed Lazlo
to saccade and track with human-like smoothness, pace and accuracy.
Algorithms for color processing, optic flow, and disparity computation
were developed. The attentional software modules are the first layer
of a more complicated system which will next incorporate the learning
of object recognition, trajectory tracking, and naive physics understanding
during the natural interaction of the robot with the environment.
For more information see:
Giorgio Metta. "An Attentional System for a Humanoid
Robot Exploiting Space Variant Vistion," Submitted to IEEE-RAS International
Conference on Humanoid Robots 2001, Tokyo, Japan, Nov. 22--24, 2001.
[Back to Top]
Kismet
- Vocabulary Management
Kismet needs to acquire a vocabulary relevant to
a human's purpose. Towards this goal, first, we have implemented a command
protocol for introducing vocabulary to Kismet. Second, we have developed
an unsupervised mechanism for extracting candidate vocabulary items
from natural continuous speech. Third, we have analyzed the speech used
in teaching Kismet words in order to determine whether humans naturally
modify their speech in ways that would enable better word learning by
the robot.
For more information see:
Paulina Varchavskaia, Paul Fitzpatrick and Cynthia
Breazeal. "Characterizing and Processing Robot-Directed Speech," Submitted
to IEEE-RAS International Conference on Humanoid Robots 2001, Tokyo,
Japan, Nov. 22-24, 2001.
Paul Fitzpatrick. "From Word-spotting to OOV Modelling,"
Term Paper for MIT Course 6.345, Cambridge, MA, 2001.
[Back to Top]
Head Pose Estimation
We developed a fully automatic system for recovering
the rigid components of head pose. The conventional approach of tracking
pose changes relative to a reference configuration can give high accuracy
but is subject to drift. In face-to-face interaction with a robot, there
are likely to be frequent presentations of the head in a close to frontal
orientation, so we used that to make opportunistic corrections. Tracking
of pose was done in an intermediate mixed coordinate system chosen to
minimize the impact of errors in estimates of the 3D shape of the head
being tracked. This is vital for practical application to unknown users
in cluttered conditions.
Watch it in action (Quicktime movie):
This video clip shows the pose of a subject's head
being tracked. The initial pose of the head is not known. Whenever the
head is close to a frontal position, its pose can be determined accurately
and tracking is reset. In this example, the mesh is shaded in two colors,
showing where the left and right parts of the face are believed to be.
For more information see:
Paul Fitzpatrick. "Head Pose Estimation Without
Manual Initialization," Term Paper for MIT Course 6.892, Cambridge,
MA, 2001.
[Back to Top]
Process Learning
Communicating a task to a robot will involve introducing
it to actions and percepts peculiar to that task, and showing how these
can be structured into the complete activity. In this work, the structure
of the task is communicated to the robot first. Examples of the activity
are presented, with any unfamiliar actions and percepts being accompanied
by verbal annotation. This allows the robot to identify the role these
components need to play within the activity, using Augmented Markov
Models.
Watch it in action (Quicktime movie):
This video clip shows part of a training session
in which Kismet is taught the structure of a sorting task. The first
part shows Kismet acquiring some task-specific vocabulary -- in this
case, the word "yellow". The robot is then shown green objects being
placed on one side, and yellow objects being placed on another. Throughout
the task the presenter is commenting in the shared vocabulary. Towards
the end of the video, Kismet makes predictions based on what the presenter
says.
[Back to Top]