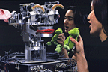- Adaptation of Arm Stiffness
Cog learns a feed forward command force function
that is dependent on arm posture but independent of stiffness. This
adaptation of stiffness parallels human reaching in which there is higher
stiffness at the endpoints and lower stiffness during the middle of
a reach. It allows Cog to reach to points in the arm's workspace with
greater accuracy, gives Cog a more human-like range of dynamics and
allows for safer and more intuitive physical interaction with humans.
Watch it in action (Quicktime movie):
This clip shows the arm stiffness before and after
Cog learns the implications of gravity. Before learning the movements
are less accurate and exact. During learning Cog samples the postures
of its workspace and refines the force function it uses to supply feed
forward commands to posture its arm. Learning results in improved arm
movement.  [12.6MB]
[12.6MB]
[Back to Top]
- Reflex Inhibition:
Inhibition of extreme movements prevents robotic
failure. Cog uses learned reflex inhibition for coordinated joint movement
and distribution of a movement over as many degrees of freedom as possible,
avoiding saturation of a few joints. During learning Cog explores the
gross limits of its torso workspace by the action of reflexive movements.
As it reaches joint extremities, a simulated pain model results in modification
of a reflex to constrain its movements to avoid physically harming itself
and to operate the torso primarily in a state of balance
Watch it in action (Quicktime movie):
In this clip Cog's torso is moving randomly under
reflexive control. When extremities are reached, Cog's model of pain
is activated and the associated reflex is refined to reduce the extent
of its extremity. As adaptation proceeds, Cog learns to balance itself.
[13.4MB]
[Back to Top]
- Dynamic Configuration of Multi-joint Muscles:
To facilitate development of a multi-joint muscle
model for controlling Cog, a graphical user interface (GUI) displays
the movement of Cog in terms of Cog's muscle model overlaying Cog's
joints. The muscle model is reconfigurable at run time through the GUI.
Watch it in action (Quicktime movie):
Cog's arm and torso movements are displayed in the
(top) of the screen. As Cog moves, the GUI shows the multi-joint muscle
model overlaying Cog's joints and how it behaves. The model itself can
be modified by the GUI shown at the (bottom) of the screen. [7.1MB]
[Back to Top]
- Hand Reflex:
Cog's two degrees of freedom hand, equipped with
tactile sensors, has a reflex that grasps and extends in a manner similar
to primate infants. Contact inside the hand causes a short term grasp,
contact to the back of the hand causes an extensive stretch.
Watch it in action (Quicktime movie): [6.4MB]
[Back to Top]
- Arm Localization:
It is difficult to visually distinguish the motion
of a robot's own arm as distinct from similar motion by humans or objects.
Cog discovers and learns about its own arm by generating a motion and
then correlating the associated optic flow with proprioceptive feedback.
It ignores any uncorrelated movements and visual data. Once Cog can
track its own arm, when it contacts an object, it discounts its own
movement in order to isolate object properties.
Watch it in action (Quicktime movie):
Cog is trying to identify its own arm. It generates
a particular rhythmic arm movement and sees this. It correlates the
visual signature of the motion with its commands to move the arm and
thus forms a representation of the arm in the image. [6.9MB]
For more information see:
Paul Fitzpatrick and Giorgio Metta,, "Towards
Manipulation-Driven Vision ", To appear, IEEE/RSJ International
Conference on Intelligent Robots and Systems, Lausanne, Switzerland,
2002. 
[Back to Top]
- Object Tapping for Segmentation:
There are cases when solely visual based object
segmentation poorly or completely fails to disambiguate an object from
its background. Cog can determine the shape of simple objects by tapping
them. This physical experimentation augments visual based segmentation.
Watch it in action (Quicktime movie):
In these two videos Cog reaches for an object as
identified by its visual attention system. It recognizes its own arm
(shown in green) and identifies the arm endpoint (a small red square).
When the object is contacted, the object's motion (differentiated from
the arm's) is used as a cue for object segmentation. It's a block! [752KB]
[744KB]
For more information see:
Giorgio Metta and Paul Fitzpatrick, "Better
Vision through Manipulation", Epigenetic Robotics Workshop, 2002.
[Back to Top]
- Mirror-Neuron Model:
Cog is able to perform manipulative actions: poking
an object away from its body and poking an object towards itself. It
uses its attentional system to locate and fixate an object and its tracking
system to follow the object trajectory. It maps visual perception into
a sequence of motor commands to engage the object. These abilities:
vision driven manipulation and mapping perception to action are prerequisites
of a mirror neuron model.

On the left, the robot establishes a causal connection
between commanded motion and its own manipulator, and then probes its
manipulator's effect on an object. The object then serves as a literal
"point of contact" to link robot manipulation with human manipulation
(on the right), as is required for a mirror-neuron-like representation.
For more information see:
Giorgio Metta, L. Natale, S. Rao, G. Sandini, "Development
of the mirror system: a computational model". In Conference on
Brain Development and Cognition in Human Infants. Emergence of Social
Communication: Hands, Eyes, Ears, Mouths. Acquafredda di Maratea, Italy.
June 7-12, 2002.
[Back to Top]
- Module Integration:
Cog has a modular architecture with components responsible
for sensing, acting and processing higher level aspects of vision and
manipulation. Cog integrates modules responsible for 14 degrees of freedom
(head, torso and arm axes) in order to reach out and poke an object.
It coordinates its head control and arm control with its visual attention,
tracking, and arm localization subsystems.
[Back to Top]
- Face Tracking:
Cog's attentional system is updated with an imported
face detector that has greater accuracy. The detector is coupled with
a face tracker that copes with non-frontal face presentations despite
the detector operating slower than frame rate. The combined systems
allow Cog to engage in tasks requiring shared attention and human-robot
interaction.
[Back to Top]
The M4 Robot
- Macaco:
The M4 robot consists of an active vision robotic
head integrated with a Magellan mobile platform. The robot integrates
vision-based navigation with human-robot interaction. It operates a
portable version of the attentional systems of Cog and Lazlo with specific
customization for a thermal camera. Navigation, social preferences and
protection of self are fulfilled with a model of motivational drives.
Multi-tasking behaviors such as night time object detection, thermal-based
navigation, heat detection, obstacle detection and object reconstruction
are based upon a competition model.
Watch it in action (Quicktime movie): [33.6MB]
[Back to Top]
Kismet
- Dynamic Subjective Response
Kismet has the ability to learn to recognize and
remember people it interacts with. Such social competence leads to complex
social behavior, such as cooperation, dislike or loyalty. Kismet has
an online and unsupervised face recognition system, where the robot
opportunistically collects, labels, and learns various faces while interacting
with people, starting from an empty database.
Watch it in action (Quicktime movie): [47MB]
For more information see:
Lijin Aryananda,, "Recognizing and Remembering
Individuals: Online and Unsupervised Face Recognition for Humanoid Robot",
To appear, IEEE/RSJ International Conference on Intelligent Robots and
Systems, Lausanne, Switzerland, 2002.
[Back to Top]
Proto-linguisitc Capabilities
Kismet uses utterances as a way to manipulate its
environment through the beliefs and actions of others. It has a vocal
behavior system forming a pragmatic basis for higher level language
acquisition. Protoverbal behaviors are influenced by the robot’s
current perceptual, behavioral and emotional states. Novel words (or
concepts) are created and managed. The vocal label for a concept is
acquired and updated.
Watch it in action (Quicktime movie): [7.8MB]
For more information see:
Paulina Varchavskaya (Varchavskaia), "Behavior-Based
Early Language Development on a Humanoid Robot", Second International
Workshop on Epigenetic Robotics, Edinburgh, UK, August 2002.
[Back to Top]