
Monitoring Network Routing and Traffic with Low Space
MIT2001-09
Start date: 11/2001
MIT LCS
Hisaki Oohara
NTT
| Research Projects | |
Monitoring Network Routing and Traffic with Low SpaceMIT2001-09 Start date: 11/2001 |
Erik D. Demaine MIT LCS Hisaki Oohara NTT |
Project summary |
|
We are developing algorithms to capture essential characteristics of network
traffic streams passing through routers, such as the most common destination
address, subject to a limited amount of memory about previously seen packets.
Project description |
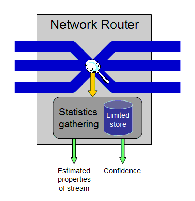
|
An accurate model and general understanding of existing Internet traffic patterns and behaviors is important for efficient network routing, caching, prefetching, information delivery, and network upgrades. Design of a network-traffic model consists of two interacting components: gathering relevant data from existing network traffic, and abstracting that data into a model with appropriate parameters. Both parts are essential. A model cannot be designed in isolation from actual traffic patterns, while on the other hand, raw data is too voluminous to suffice as a model. This project focuses primarily on the first component, but there is inherent interplay with the second component. A fundamental difficulty with measuring traffic behavior on the Internet is that there is simply too much data to be recorded for later analysis, on the order of gigabytes a second. As a result, network routers can collect only relatively few statistics about the data, and cannot spend much time per packet to collect these statistics. While hardware-specific solutions exist, they are expensive and cannot be widely deployed. The central problem addressed here is to use the limited memory of routers, on the order of a gigabyte total, to determine essential features of the network traffic stream. A particularly representative subproblem is to determine the top k sites to which the most packets are delivered, for a desired value of k. These problems are made particularly difficult by the unpredictable distributions of network traffic. It is unreasonable to assume a priori that network traffic follows a standard distribution such as Poisson or Zipf. While such properties might hold on the aggregate, they cannot generally be expected to hold over a specific link of interest in the network. For example, consider two network pipes, one with a financial web site as the dominant destination and another with a local ISP as the dominant destination. In this case, one can expect a peak on traffic to the financial site at market open and close, while the ISP, used mostly from home, will follow a Gaussian distribution centered on 7:00pm. Our goal is to characterize under what circumstances it is possible to develop efficient algorithms that have provable guarantees (possibly probabilistic) on the quality of gathered statistics based on weak assumptions on the traffic distribution. This project is a collaborative effort with Alejandro López-Ortiz and J. Ian Munro. |
Demos, movies and other examples |
The principal investigators |
Presentations and posters |
Publications |
Proposals and progress reports |
Proposals:
NTT Bi-Annual Progress Report, July to December 2001:
NTT Bi-Annual Progress Report, January to June 2002:
NTT Bi-Annual Progress Report, July to December 2002:
For more information |