|
In designing Kismet's vocalization system, we must address issues regarding the expressiveness and richness of the robot's vocal modality and how it supports social interaction. In studies with naive subjects have found that the vocal utterances are rich enough to facilitate interesting proto-dialogs with people, and we have found the emotive expressiveness of the voice to be reasonably identifiable. Furthermore, the robot's speech is complemented by real-time facial animation which enhances delivery. Instead of trying to achieve realism, we have implemented a system that is well matched with the robot's appearance and capabilities. The end result is a well orchestrated and compelling synthesis of voice, facial animation, and emotive expression that make a significant contribution to the expressiveness and personality of the robot.
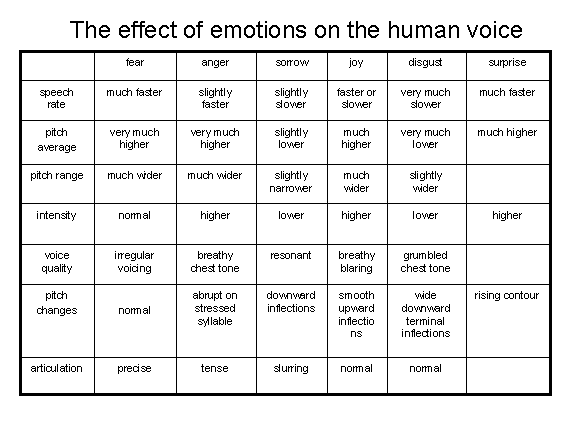
Emotion in Human SpeechThere has been an increasing amount of work in identifying those acoustic features that vary with the speaker's emotional state (see table). Emotions have a global impact on speech since they modulate the respiratory system, larynx, vocal tract, muscular system, heart rate, and blood pressure. Changes in the speaker's autonomic nervous system can account for some of the most significant changes, where the sympathetic and parasympathetic subsystems regulate arousal in opposition. For instance, when a subject is in a state of fear, anger, or joy, the sympathetic nervous system is aroused. This induces an increased heart rate, higher blood pressure, changes in depth of respiratory movements, greater sub-glottal pressure, dryness of the mouth, and occasional muscle tremor. The resulting speech is faster, louder, and more precisely enunciated with strong high frequency energy, a higher average pitch, and wider pitch range. In contrast, when a subject is tired, bored, or sad, the parasympathetic nervous system is more active. This causes a decreased heart rate, lower blood pressure, and increased salavation. The resulting speech is typically slower, lower-pitched, more slurred, and with little high frequency energy.
Expressive Synthesized SpeechWith respect to giving Kismet the ability to generate emotive vocalizations, Janet Cahn's work (e.g., the Affect Editor) is a valuable resource. Her system was based on DECtalk, a commercially available text-to-speech speech synthesizer that models the human articulatory tract. Given an English sentence and an emotional quality (one of anger, disgust, fear, joy, sorrow, or surprise), she developed a methodology for mapping the emotional correlates of speech (changes in pitch, timing, voice quality, and articulation) onto the underlying DECtalk synthesizer settings. By doing so, the parameters of the articulatory model are adjusted to bring about the desired emotive voice characteristics.
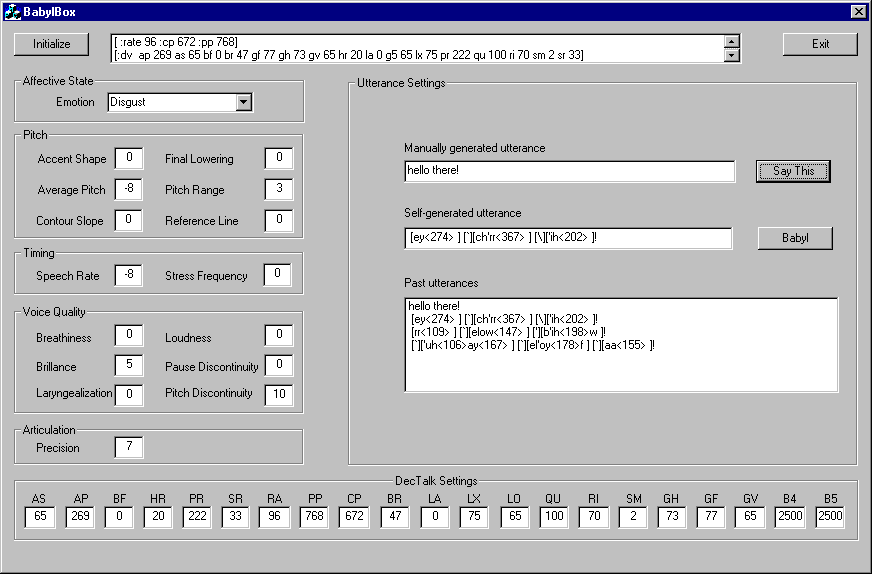
(click to see user interface) We use a technique very similar to Cahn's for mapping the emotional correlates of speech (as defined by her vocal affect parameters) to the underlying synthesizer settings. Because Kismet's vocalizations are at the proto-dialog level, there is no grammatical structure. As a result, we are only concerned with producing the purely global emotional influence on the speech signal. Cahn's system goes further than ours in considering the prosodic effects of grammatical structure as well.
Generation of UtterancesTo engage in proto-dialogs with its human caregiver and to partake in vocal play, Kismet must be able to generate its own utterances. To accomplish this, strings of phonemes with pitch accents are assembled on the fly to produce a style of speech that is reminiscent of a tonal dialect. As it stands, it is quite distinctive and contributes significantly to Kismet's personality (as it pertains to its manner of vocal expression). However, it is really intended as a place-holder for a more sophisticated utterance generation algorithm to eventually replace it. In time, Kismet will be able to adjust its utterance based on what it hears, but this is the subject of future work.
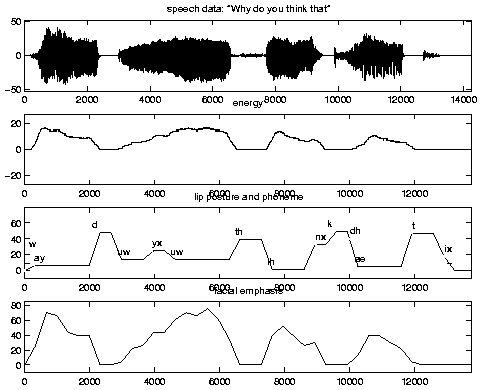
Real-time Lip SynchronizationGiven Kismet's ability to express itself vocally, it is important that the robot also be able to support this vocal channel with coordinated facial animation. This includes synchronized lip movements to accompany speech along with facial animation to lend additional emphasis to the stressed syllables. These complementary motor modalities greatly enhance the robot's delivery when it speaks, giving the impression that the robot ``means'' what it says. This makes the interaction more engaging for the human and facilitates proto-dialog.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||