The best way to test design principles is to put them into practice. For information spaces, this means finding a collection of information to organize, deciding on task and purpose, and weighing and applying the principles described to arrive at a solution.
The first problem thus approached was to design an information space for the Journal of Artificial Intelligence Research. This work was undertaken before the study of museum exhibits had begun, so it was informed by a smaller set of principles than were presented here. It was intended as an early experiment, a project in which a certain set of ideas were be tried out and their consequences evaluated. Although data on how people used the space was collected, a rigorous usability study was not the goal. Instead, aspects of the user interface were improved over time in response to individual users' feedback.
In this chapter we describe the nature of the information to be organized, the tasks supported by the space, how it was designed, and evaluate it as a new source of principles for design. In creating this information space, we discovered that the designer should:
The JAIR information space is an information access environment for the Journal of Artificial Intelligence Research, whose contents are available on-line. Such an environment is designed to assist the user in obtaining information which fulfills an information need [Belkin, 1978]. In this case, the space assists the user in determining which articles are of interest and provides a means for downloading and displaying relevant articles.
The design of such an information access environment must take into account a typical user's knowledge of the domain, his familiarity with search tools and search strategies, and the nature of the information accessible from the environment [Marchionini, 1995]. For the JAIR information space the typical user is assumed to be familiar with main topics of research within the field of artifical intelligence and the terminology used to describe them. Also assumed is familiarity with hypertext, common user interface widgets (such as buttons and scrollbars), direct-manipulation interfaces, and full-text search capabilities.
The nature of the information accessed through the space is described in the Journal's charter, excerpted here:
``JAIR's editorial board is dedicated to the rapid dissemination of important research results to the global AI community. The journal's scope encompasses all areas of Artificial Intelligence, including automated reasoning, cognitive modeling, knowledge representation, learning, natural language, neural networks, perception, and robotics.''
Specifically, this space encompasses all of the approximately 100 articles published in the Journal (at the time of writing). All of them are available in electronic form and can be downloaded and displayed by the user on demand from the Journal's Web site.
The specific tasks supported by the space are search, browsing, and retrieval. For this document collection, search is the ability to locate an an article based on specific criteria, such as title and author, or by the full-text of their contents. Browsing is scanning titles and abstracts of related articles of interest. Retrieval is the downloading of an entire article for reading.
Once a set of user tasks has been decided on, the next task is how to represent information in the space. One way to do so is to assign dimensions or attributes to each item of information, and then to choose the mode of presentation for those dimensions.
For this space, the articles were placed in two dimensions, but the viewpoint is manipulable in three dimensions. Leaving the articles in two dimensions prevents occlusion, which is a recurring problem in a number of 3-D information visualizations [Carrière and Kazman, 1995] [Chuah et al., 1995] [Chalmers et al., 1996]. The third dimension can then be left to represent additional information about the articles.
To make that dimension visible, the two-dimensional layout is displayed in orthographic projection with a manipulable viewpoint. The orthographic projection preserves distance relationships consistently throughout (as opposed to a perspective projection). The manipulable viewpoint allows the user to adjust the visualization to shift focus. It also prevents occlusion and gives the impression of exploring a concrete object instead of viewing an image.
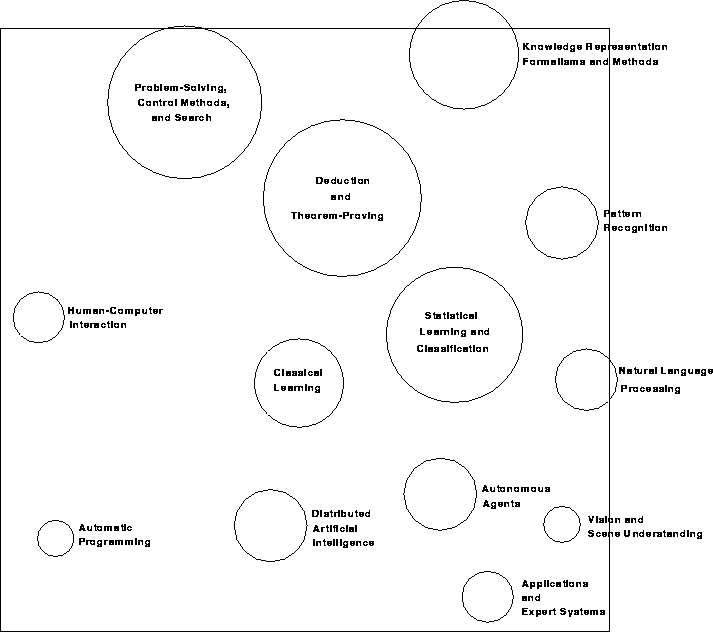
Previous designs that arrange documents in two dimensions use the documents' term-vector similarity to each other [Chalmers, 1993] or preset queries [Olsen et al., 1993]. Instead, we chose to first classify the articles into categories based on the major subtopic of AI they addressed, then to use that classification as the basis for spatial layout. In this way, a two-level hierarchy is used for positioning: primary positioning among categories and secondary positioning within categories. The circular perimeters of the categories makes the layout resemble a projected, one-deep cone tree [Robertson et al., 1991]. For the layout of the categories in information space, see Figure 7-2.
Since the classification was a simple partition on the articles, the articles are positioned equidistantly about category centers. The radius of a circle category is proportional to the square root of the number of articles in the category, so that the area of the circle is proportional to its size. In this way, a judgment can be made about the relative distribution of articles among topics. This arrangement also facilitates browsing with mouse movements by maintaining a regular spacing among the articles.
The classification was performed manually. The topics for AI were chosen from the 1991 ACM Classification System. Seventeen of the articles were given a primary category and a secondary category because they were judged relevant to more than one topic. These secondary category assignments were used as the metric for category similarity; the more articles assigned to a pair of categories, the higher the similarity value.
Kruskal's multidimensional scaling algorithm (MDS) was used to arrange
the locations of categories in two dimensions [Kruskal, 1964a]
[Kruskal, 1964b]. MDS attempts to find an arrangement of
items in which the rank-ordering of dissimilarities among items is
most closely preserved by the ordering of distances between them. In
this case, dissimilarity between categories i and j that have
shared(i,j) articles assigned to both was computed by
MDS performs a gradient search in a nm-dimensional space to arrange n items in an m-dimensional space. The search attempts to minimize the stress of an item arrangement, which measures how well the distances between items preserve the dissimilarity measure. Kruskal's algorithm was modified to subtract the radii of a pair of categories from the distance between them to prevent category overlap. The desired interpretation of the category layout is that, on average, categories with more shared articles are closer together, and more similar in that sense, than categories with fewer shared articles.
Colors were chosen to emphasize the information-bearing elements of the visualization, and to render structural elements more subtly. This prevents the visual distractions Tufte [Tufte, 1990] calls ``chartjunk,'' which hinder perception and interpretation without adding information content to the visualization. For example, the most important parts of the visualization for determining topic relevance and article access are bright green and yellow. Structural features, such as the category perimeters and the ground plane, are in dim gray.
Information retrieval using a full-text index has proved to be an effective information access tool [Salton, 1989]. The JAIR information space permits multi-term searches, with the results displayed as lines rising above icons. Two features are worth noting:
Since downloading and viewing articles are time-consuming operations, any means of conveying more information about an article's contents beforehand is useful. The information space is augmented with a details-on-demand [Shneiderman, 1996] feature that displays an article's full bibliographic entry and an excerpt of the abstract when the mouse pointer is moved over the corresponding article-icon. This facilitates rapid browsing of a category's contents.
Finally, when accessing an article, all of the document formats associated with the article are presented as choices for downloading. In this way, the user can choose to view the article as HTML in the browser window, or download compressed or uncompressed PostScript versions. Each of these options has tradeoffs in download time and convenience for viewing, saving, or printing. Many articles also have additional files as appendices, which are accessible from the same list.
The ideal implementation environment would be integrated with the existing online information infrastructure in which JAIR is published and require minimal user maintenance or client resources. The Java implementation and associated libraries integrated with popular Web browsers satisfy the first two criteria, but resource requirements are problematic for older systems. Performance degradation occurs primarily in viewpoint manipulation, so that the application is slow, but functionally usable, as the articles are still accessible from the browsable lists.
The information space was implemented and made publicly available on the JAIR Web site.4
This section contains the instructions given to users of the space when they first access it.
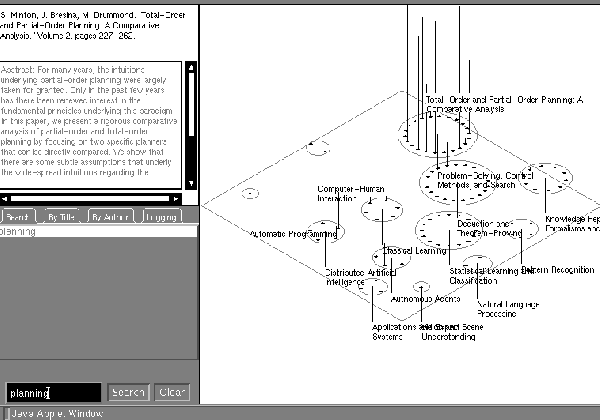
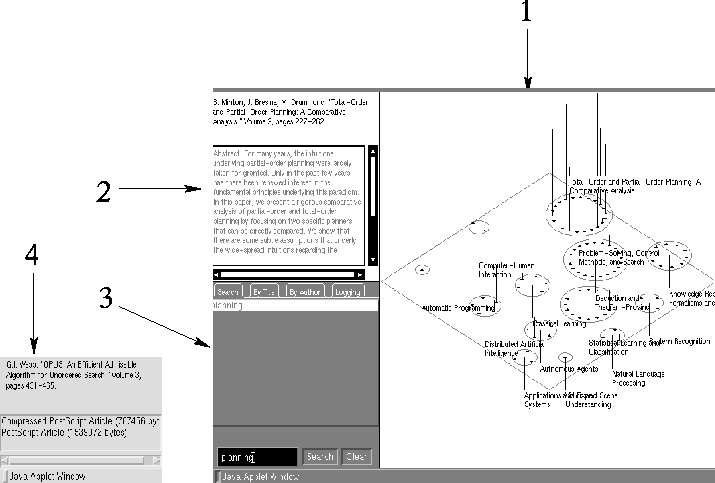
Referring to Figure 7-3, Panel 1 contains a ground plane situated in a projection of a three-dimensional space. The yellow square icons on the plane represent published articles in the Journal of Artificial Intelligence Research. Each icon is arranged equidistantly about a label describing a category to which the article has been assigned. The area of the circle around each category label is directly proportional to the number of articles assigned to that category. The categories are arranged so that a pair of categories which have more articles that could have been assigned to both are closer together than a pair of categories that have fewer or no such co-assignments.
The user can manipulate his viewpoint into this space by using the mouse to pan, zoom, and rotate it. Passing the pointer over an icon will cause the full bibliographic entry and an excerpt of the abstract to appear in Panel 2. Clicking on an icon will will cause the Access window (4) to appear, which lists all of the files associated with that article (an article may have versions in PostScript or HTML, and the PostScript file may be compressed). Some articles also have additional files on-line as appendices. Double-clicking on a file description in the Access Window will cause it to be loaded into the user's browser; whether that file is displayed in the browser, displayed by an external program, or saved to disk depends on the browser's configuration.
The tabbed panel (3) allows the user to construct full-text queries of the articles, as well as to browse the articles by author and title. Query results are displayed as segmented lines drawn upward from the icons on the ground plane. The length of each segment is proportional to the number of occurences of a term in the query. The bottom most segment of the line corresponds to the first search term, the penultimate the second, and so forth. Search terms are kept in a history list on the search panel, and those used in the last query are highlighted. Terms can be added or removed to construct a new query by selecting and deselecting words from the list.
The articles can also be browsed by scrollable lists sorted by author and title in the same tabbed panel. Double-clicking on an item in these lists will list its files in the Access window for downloading.
After the information space was made available to the public, numerous responses were received by electronic mail. Some suggested usability enhancements to the information space which were later added, including:
As articles are continually published by the Journal, they need to be
integrated into the information space. Since the layout was based on
the relationships between categories, and not the articles themselves,
the articles can be incrementally added to categories without greatly
affecting the category layout. The only change is that the radius of
each category grows as
![]() .
If a newly published article were
relevant to more than one category, however, then it would be
necessary to run the multidimensional scaling algorithm again and
rearrange the categories.
.
If a newly published article were
relevant to more than one category, however, then it would be
necessary to run the multidimensional scaling algorithm again and
rearrange the categories.
Two different navigation styles were also tried for the space. In the first, the viewpoint was static, so that it appeared that the user was manipulating the ground plane that held the articles. The plane could be rotated or zoomed to focus on a smaller part of the space. In this way, the space acts more like a map that is directly manipulated by the user.
The second mode of interaction was one in which the viewpoint was dynamic; it could be panned, zoomed, and rotated, giving the impression that the user was moving through the space. This style is more navigational, giving the user a sense of having a location and orientation in the space. These two styles can be selected by the user in the ``Options'' tab.
The evaluation presented here will focus on two questions we can ask about an information space. The first is how well it supports useful tasks, in this case, search, browsing, and retrieval. The second asks what are the engineering costs of creating and maintaining the environment.
Documents can be retrieved from the space by two search methods. If the user knows the title or author of a desired article, the article can be retrieved by scrolling the alphabetical title and author indices. If the user knows words likely to appear in articles of interest, he can perform a full-text search and see the distribution of search results on the articles in the space. This illustrates a benefit of using a map to represent an information space; it allows interaction between search and browsing, so that a full-text query or a selection from an index can give the user a starting point for browsing.
Browsing within categories is accomplished by moving the mouse pointer from document icon to document icon and examining the abstract and article title that are displayed in the upper-left hand corner. Since no other user action is required, he can rapidly browse the articles in a category by rotating the mouse pointer around the circle of document icons. This action requires precise mouse movements, and may pose difficulties for some users.
Browsing among categories is done by making a larger move of the mouse pointer from one category circle to another. Ideally, the similarity metric used to arrange the categories should indicate some relationship between the categories, giving this larger move some clear semantics in the space. However, the use of an arrangement in a space of lower dimension than the n(n-1)/2 possible relationships between categories creates false positives: categories that are placed close together but that are dissimilar.
Also, many of the inter-category distances are about the same for the larger categories, making fine discriminations about similarity difficult. The category layout is best seen as a rough arrangement that gives some structure to the space, without being a driving criterion for browsing actions.
To get some sense of how users were browsing through the space, usage data was collected for an interval of two weeks after the space was made available to the public. The sequence of articles over which the user passed the mouse pointer and which articles were downloaded was recorded. The sampling was intended simply to obtain examples of user behavior, and not for statistical evaluation.
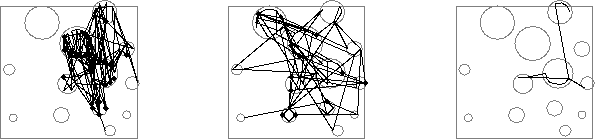
Three logs showing different kinds of browsing behavior are visualized in Figure 7-4. The browsing path between successive articles is drawn as a line, and a downloaded article is marked with a dot. The user on the left browsed a subset of the categories extensively, and downloaded several articles from them. The middle user covered every category, moving quickly from one to the other. The user on the right browsed primarily within two categories and made only four long-distance moves between categories. The variety of browsing behaviors observed suggests that browsing is driven both by user style and needs and the structure of the space. Many users browsed only briefly, however. In the sample taken, about 60 percent of the logs showed very brief or no browsing activity.
For any information access environment, issues of design cost and maintenance are of practical importance. The JAIR information space had a high design cost; creating the initial document layout required hand-classifying the articles, noting which had primary and secondary categories, and running the multidimensional scaling algorithm. However, once the initial layout was in place, adding additional articles as they were published only requires classifying them appropriately and adding them to the bibliographic database, without recomputing the initial layout (unless they are classified in more than one category). The JAIR space could be characterized as having a large fixed cost, but a smaller marginal cost.
Another engineering issue is how well the design scales to include more articles. Two dimensions along which the space can scale with more articles and categories are the area occupied by the categories and levels of abstraction in the categorization. However, as these increase, issues of visibility and navigation come to the forefront - can we make every article visible (and accessible), and if not, how do we move between views of sets of articles? Although the space could be adapted to accomodate these requirements, its current presentation was designed for a few hundred articles at most.
The design could generalize to search and browse document collections with a meaningful top-level categorization. When bibliographic information for the documents is available, the list browsing and details-on-demand features can also be used. Full-text searching is also possible when the text of the documents is available.
Although the JAIR information space was designed before many of the principles described earlier were set, it does exemplify the use of several of them. In particular,
Allow for multiple levels of engagement and understanding. The user can first skim article titles by rapidly browsing with the mouse. For more detail, he can read abstracts and bibliographies in the upper-left window. Finally, he can select and download entire articles relevant to his need.
Create regions of differing visual character. Each category defines an enclosed region in the space, demarcating a collection of articles on a similar subtopic of AI. The user can browse a region and know that all of the articles within are related.
Use survey views (give navigators a vista or map). The space can show all of the articles at once, and lets the user make large moves in the space if desired. The map succintly displays the distribution of articles across the categories, and lets the user maintain his orientation in the space.
Provide signs at decision points to help wayfinding decisions. Each region has a label identifying the category of the articles it contains below the ground plane, and the title of each article appears above the ground plane. In a survey view, when there are many choices where to go next, signs provide important directions to the user.
Use route data for visualization, dynamism, and debugging. Although users' paths were not visualized in the space, the log data allowed the designers to reconstruct them later. The reconstructed paths demonstrated that users have different browsing strategies in the space.
Provide layers of information on the map. The additional dimension provided by the survey view was used to visualize the results of full-text queries on the articles. This additional layer of information on the map gave users starting points for browsing and retrieval.
Some new principles were discovered from the experience of designing, maintaining, and improving the JAIR information space: